[TOC]
- Title: Grounding Language Models to Images for Multimodal Generation
- Author: Jing Yu Koh et. al.
- Publish Year: 31 Jan 2023
- Review Date: Mon, Feb 6, 2023
- url: https://arxiv.org/pdf/2301.13823.pdf
Summary of paper

Motivation
- we propose an efficient method to ground pre-trained text-only language models to the visual domain
- How
- we keep the language model frozen, and finetune input and output linear layers to enable cross-modality interactions. This allows our model to process arbitrarily interleaved
Contribution
- our approach works with any off-the-shelf language model and paves the way towards an effective, general solution for leveraging pre-trained language models in visually grounded settings.
Related work
LLMs for vision-and-language
- we differ from previous work in that our model is capable of generating coherent multimodal output: Flammingo is incapable of producing visual output.
efficient adaptation of pretrained models
- our work builds upon the insights and methods from these prior works. While previous models mostly focus on generating text-only outputs, our model is capable of processing arbitrarily interleaved image-text inputs to generate coherent interleaved image-text outputs.
Method
- We learn translation parameters (parameterized as linear layers) to cast images into text space,
- and translate text embeddings into visual space. (cycle???)
two training methods
- image captioning
- image-text retrieval

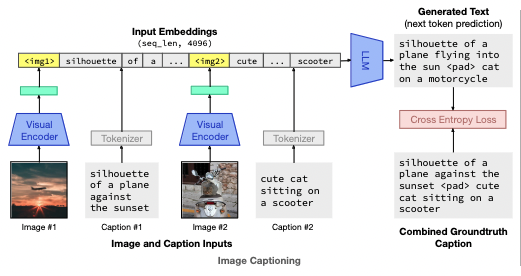
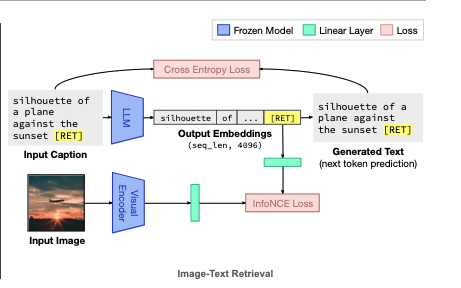
How does it output images
- it can do coreferencing to select the appropriate images

Good things about the paper (one paragraph)
- the framework has the same function as CLIP but it utilises the pretrained large-scale visual language models.