
[TOC]
- Title: Guiding Pretraining in Reinforcement Learning With Large Language Models
- Author: Yuqing De, Jacob Andreas et. al.
- Publish Year: 13 Feb 2023
- Review Date: Wed, Apr 5, 2023
- url: https://arxiv.org/pdf/2302.06692.pdf
Summary of paper

Motivation
- intrinstically motivated exploration methods address sparse reward problem by rewarding agents for visiting novel states or transitions.
Contribution
- we describe a method that uses background knowledge from text corpora to shape exploration.
- This method, call Exploring with LLMs, reward an agent for achieving goals suggested by a language model prompted with a description of agent’s current state.
Some key terms
How does ELLM work
- ELLM uses a pretrained large language model to suggest plausibly useful goals in a task-agnostic way.
- task-agnostic -> kind of exploration
- ELLM prompts an LLM to suggest possible goals given an agent’s current context and reward agents for accomplishing those suggestions.
- as a result, exploration is biased toward completion of goals that are diverse, context-sensitive and human-meaningful.
- ELLM-trained agents exhibit better coverage of useful behaviours during pretraining, and outperform or match baselines when fine-tuned on downstream tasks
why intrinsically motivated exploration reward is not good
- not everything novel or unpredictable is useful: noisy TVs and the movements of leaves on a tree may provide an infinite amount of novelty, but do not lead to meaningful behaviours.
- more recent approaches compute novelty in higher-level representation space such as language, but can continue driving the agent to explore behaviours that are highly unlikely to every be useful
Method
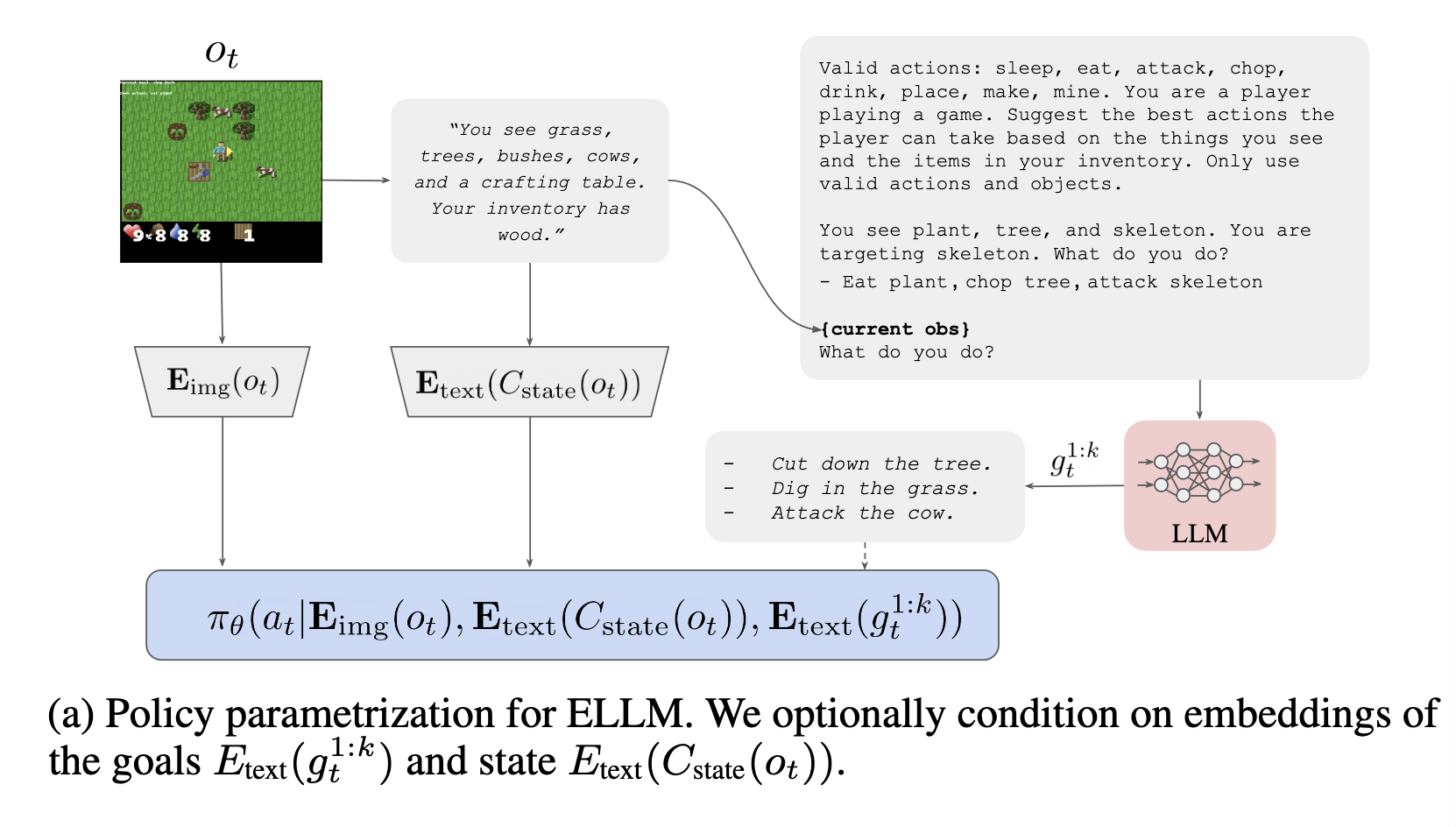
- $C_{state}(o_t)$, $C$ is the state captioner
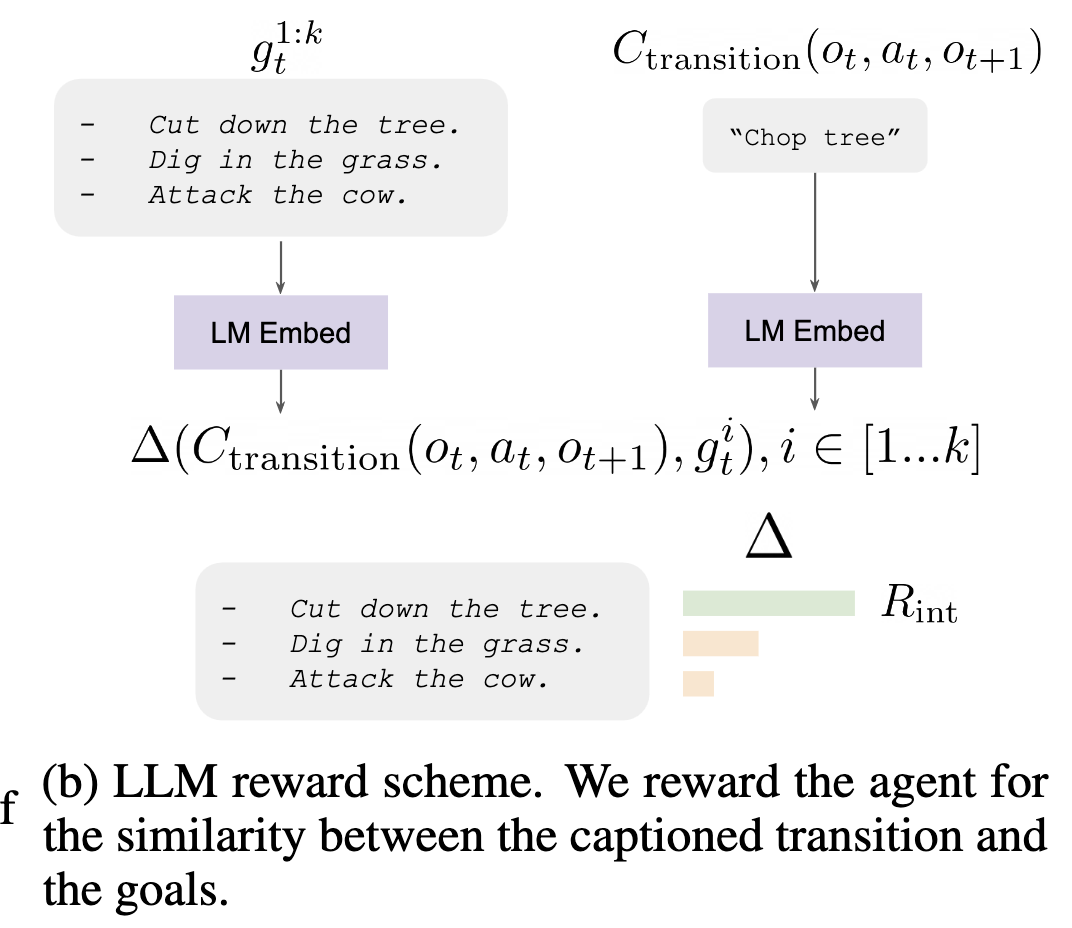
- $\Delta$ is the cosine similarity function.
- we reward the agent for achieving any of the $k$ suggested goals by taking the maximum of the goal-specific rewards
Potential future work
- we may want to reuse the state captioner for our future work
- check Appendix H of the paper
