[TOC]
- Title: Improved Baselines With Visual Instruction Tuning
- Author: Haotian Liu et. al.
- Publish Year: Oct 5 2023
- Review Date: Sun, Oct 8, 2023
- url: https://arxiv.org/pdf/2310.03744.pdf
Summary of paper

Motivation
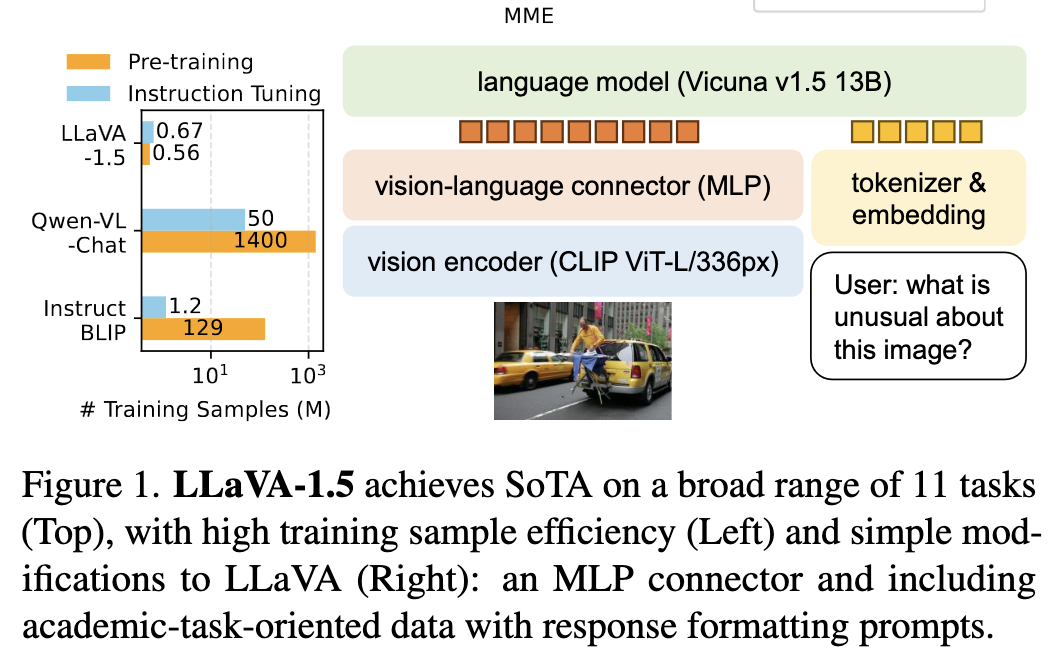
- we show that the fully-connected vision-language cross-modal connector in LLaVA is surprisingly powerful and data-efficient.
Contribution
- with simple modifications to LLaVA, namely, using CLIP-ViT with an MLP projection and adding academic-task-oriented VQA data with simple response formatting prompts, they establish stronger baseline.
Some key terms
Improvement one: MLP cross modal connector
Improvement two: Incorporating academic task related data such as VQA
- the two improvements lead to better multimodal understanding capabilities
Background
instruction-following LMM
- training an instruction-following LMM usually follows a two-stage protocol.
- first, the vision-language alignment pretraining stage leverage image-text pairs to align the visual features with the language model’s world embedding space (BLIP)
- second, the visual instruction tuning stage tunes the model on visual instructions, to enable the model to follow user’s diverse requests on instructions that involve the visual contents.
existing limitation
- LLaVA failed short on academic benchmarks that typically require short-form answers.
- this was attributed to the fact that LLaVA has not been pretrained on large-scale data.
- also we need a more proper prompt to regularize the output length

MLP Vision Language Connector
- by changing from a linear projection to an MLP, they found that improving the vision-language connector’s representation power with two layer MLP can improve LLaVA’s multimodal capabilities, compared with the original linear projection design.