[TOC]
- Title: Generalisable episodic memory for Deep Reinforcement Learning
- Author: Hao Hu et. al.
- Publish Year: Jun 2021
- Review Date: April 2022
Summary of paper
Motivation
The author proposed Generalisable Episodic Memory (GEM), which effectively organises the state-action values of episodic memory in a generalisable manner and supports implicit planning on memorised trajectories.
so compared to traditional memory table, GEM learns a virtual memory table memorized by deep neural networks to aggregate similar state-action pairs that essentially have the same nature.
GEM is able to do implicit planning by performing value propagation along trajectories saved in the memory and calculating the best sequence over all possible real and counterfactual combinatorial trajectories.
Some key terms
Traditional discrete model-free episodic control
The key idea if to store good past experience in a tabular based non parametric memory and rapidly latch onto past successful policies when encountering similar states, instead of waiting for many steps of optimization.
When different experiences meet up at the same state-action pair (s,a), model-free episodic control aggregates the values of different trajectories by taking the maximum return R among all these rollouts starting from the moment (s, a)
At the execution time, we select the action according to the maximum Q-value of the current state, if there is no exact match of the state, MFEC performs a KNN loop up to estimate the state-action Q values
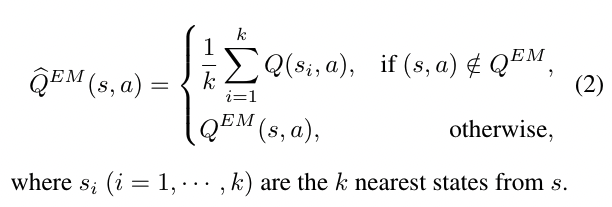
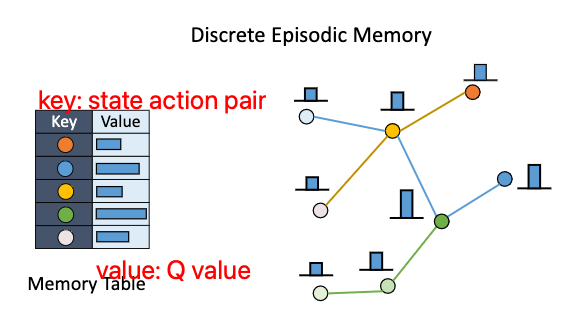
Generalisable episodic memory
Somehow it is just like critic network to measure the Q value of the state action pair.
Major comments
Maybe this paper just want to say that for Actor Critic model, the Critic network that estimate the Q value can be treated as Generalisable Episodic Memory table.