[TOC]
- Title: Strength in Numbers: Estimating Confidence of Large Language Models by Prompt Agreement
- Author: Gwenyth Portillo Wightman et. al.
- Publish Year: TrustNLP 2023
- Review Date: Tue, Feb 27, 2024
- url: https://aclanthology.org/2023.trustnlp-1.28.pdf
Summary of paper

Motivation
- while traditional classifiers produce scores for each label, language models instead produce scores for the generation which may not be well calibrated.
- the authors proposed a method that involves comparing generated outputs across diverse prompts to create confidence score. By utilizing multiple prompts, they aim to obtain more precise confidence estimates, using response diversity as a measure of confidence.
Contribution
- The results show that this method produces more calibrated confidence estimates compared to the log probability of the answer to a single prompt, which could be valuable for users relying on prediction confidence in larger systems or decision-making processes.
- in one sentence: try multiple times, get the mean, mean is more robust and consistent.
Some key terms
calibrated confidence score
- a model is considered well calibrated if its prediction probabilities are aligned with the actual probability of its predictions being correct.
- if a model says an answer has 90% confidence, then we should expect it to be correct 90% of the time.
summarized method
consider two approaches
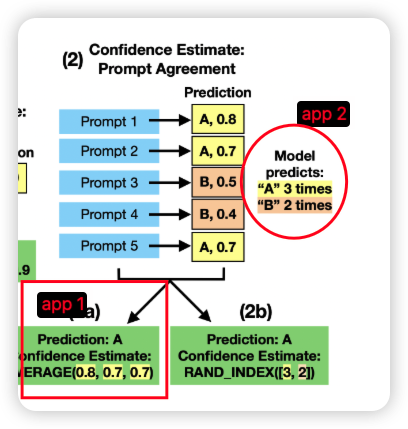
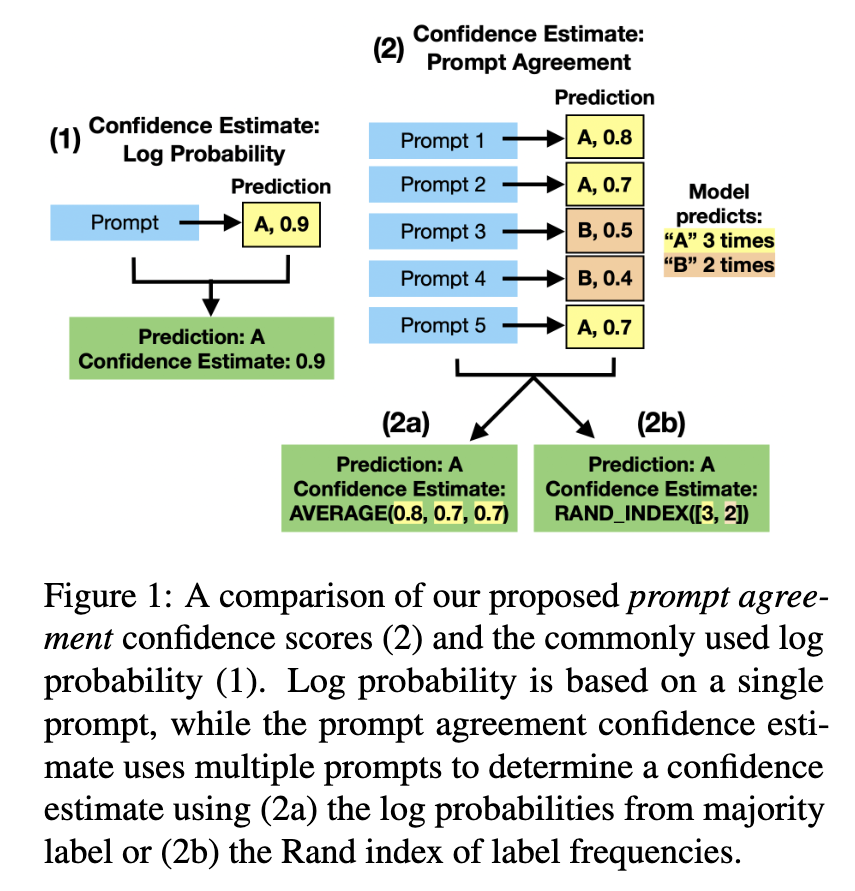
- measure the log probability of the response across multiple prompts that agree on the same answer.
- measure the diversity in answer across different prompts in the model output, concluding that answers which appear in more responses have relatively higher confidence.
- the diversity measures the confidence, for example, suppose that for a given question queried across ten prompts, the model always replies eggplant. For a second question queried with the same prompts, the model answers potato (5 times) and eggplant, cucumber, squash, carrot and kale. We would say the model is more confident in its answer to the first question.
directly ask GPT about the confidence
ref: Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. Teaching models to express their uncertainty in words.
it suggests that model have some notion of confidence in MCQ tasks
Results
- the confidence estimate based on multiple prompts more accurately reflects the chance that a model is correct as compared to log probabilities from a single prompt.
Summary
Our experiments with T0++, FLAN-T5-XXL, and GPT-3 suggest that prompt agreement provides a more calibrated confidence estimate than the typical approach of log probability from a single prompt