[TOC]
- Title: Retrieve Fast, Rerank Smart: Cooperative and Joint Approaches for Improved Cross-Modal Retrieval
- Author: Gregor Geigle et. al.
- Publish Year: 19 Feb, 2022
- Review Date: Sat, Aug 27, 2022
Summary of paper
Motivation
they want to combine the cross encoder and the bi encoder advantages and have a more efficient cross-modal search and retrieval
- efficiency and simplicity of BE approach based on twin network
- expressiveness and cutting-edge performance of CE methods.
Contribution
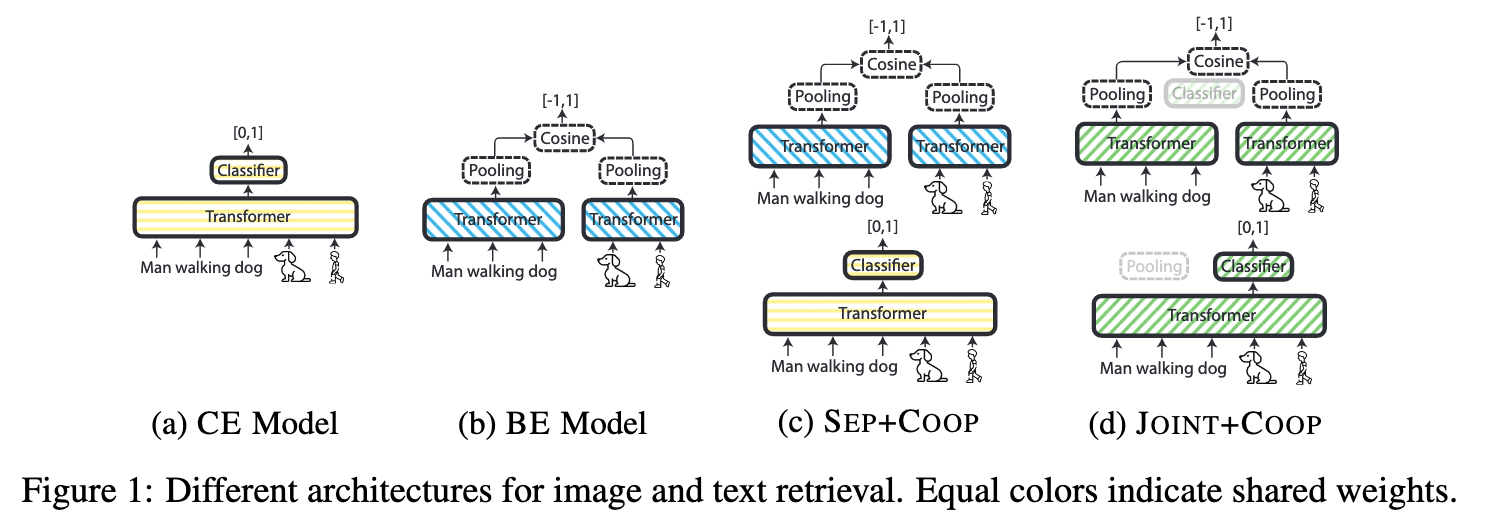
We propose a novel joint Cross Encoding and Binary Encoding model (Joint-Coop), which is trained to simultaneously cross-encode and embed multi-modal input; it achieves the highest scores overall while maintaining retrieval efficiency
Some key terms
Bi-encoder approach
encodes images and text separately and then induces a shared high-dimensional multi-modal feature space. very common
cross attention based approach
apply a cross attention mechanism between examples from the two modalities to compute their similarity scores
- limitation of cross attention approach
- they have extremely high search latency
- may results in inflated and misleading evaluation performance when using small benchmarks
Methodology
Pretraining part
- Similar to masked language modelling (MLM) in the text domain, multi-modal Transformer models are trained with self-supervised objectives. For pretraining, image-caption datasets (i.e., MSCOCO, Flickr30k, Conceptual Captions and SBU) are utilised
- The pretrained multi-modal model is subsequently fine-tuned with multi-modal downstream task data.
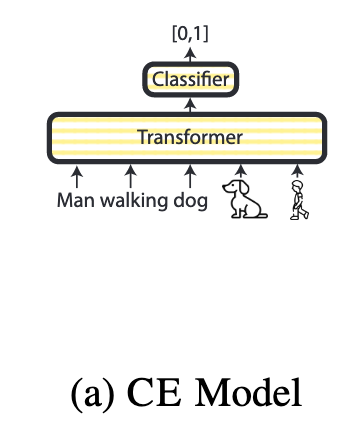
cross-encoder training
- training
- A pretrained model receives as input positive and negative pairs of image and captions
- A binary classification head is placed on top of the Transformer model, where the contexualized embedding of the [CLS] token is passed into the classification head.
- The weight of classifier head together with the Transformer are fully fine-tuned using a binary cross-entropy (BCE) loss
bi-encoding training
- training
- the objective of the twin network is to place positive training instances (image, caption) (i,c) closely in the shared multi-modal space, while unrelated instance should be placed farther apart. This is formulated through a standard triplet loss function. It leverages (i,c,c’) and (i,i’, c) triplets, where (i,c) are positive image-caption pairs from the training corpus, while c’ and i’ are negative examples sampled from the same corpus such at (i, c’) and (i’, c) do not occur in the corpus, the triplet loss is then
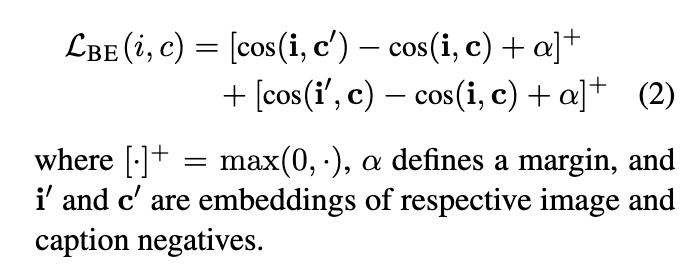
bi-encoding retrieval
- the BE approach enables pre-encoding of all items for efficient retrieval loop-up and thus this approach can scale to even billions of images
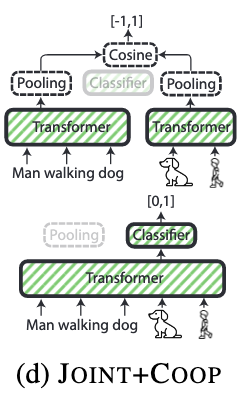
Joint Coop process
- Use Bi-Encoder to retrieve top K first and then use Cross Encoder to rank based on the Sigmoid classification score [0, 1]
Training setup and hyperparameters

Good things about the paper (one paragraph)
Github page: https://github.com/UKPLab/MMT-Retrieval
Major comments
Minor comments
Incomprehension
Potential future work
Try this to get similarity score for multi-modality data
Also try DeepNet to solve gradient vanishing problem