[TOC]
- Title: Dynamic Planning With a LLM
- Author: Gautier Dagan et. al.
- Publish Year: 11 Aug 2023
- Review Date: Sun, Jan 21, 2024
- url: arXiv:2308.06391v1
Summary of paper

Motivation
- Traditional symbolic planners can find optimal solutions quickly but need complete and accurate problem representations. In contrast, LLMs can handle noisy data and uncertainty but struggle with planning tasks. The LLM-DP framework combines LLMs and traditional planners to solve embodied tasks efficiently.
- Traditional Planner need maximal information
Some key terms
Hallucination
- However, employing LLMs in em- bodied agents, which interact with dynamic envi- ronments, presents substantial challenges. LLMs tend to generate incorrect or spurious information, a phenomenon known as hallucination, and their performance is brittle to the phrasing of prompts (Ji et al., 2022).
Convert to PDDL
- Previous work by (Liu et al., 2023) has shown that LLMs can generate valid problem files in the Planning Domain Definition Language (PDDL ) for many simple examples.
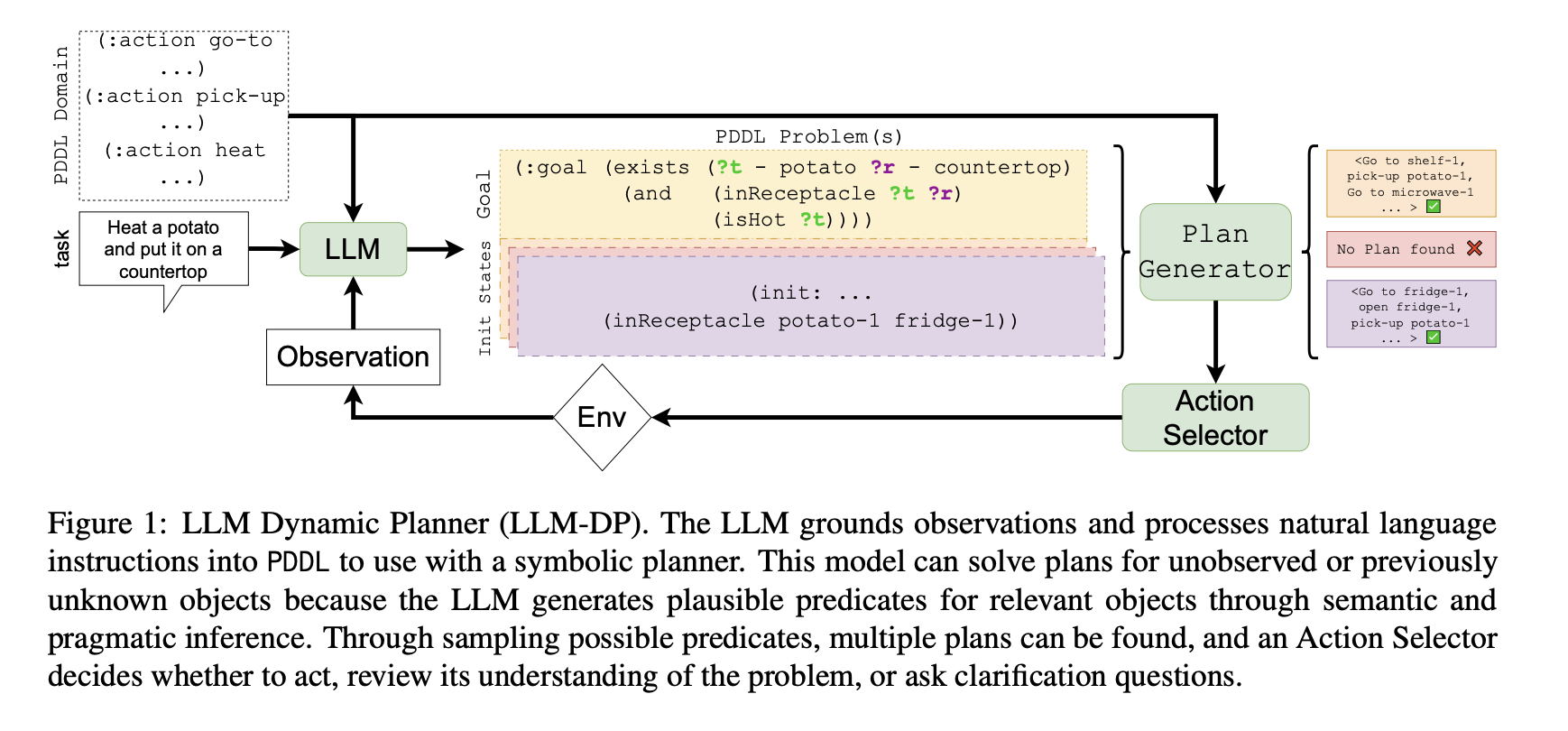
LLM Dynamic Planner Overview
-
a neuro-symbolic framework that integrates an LLM with a symbolic planner to solve embodied tasks.
-
we use a set of three in-context examples that are fixed for the entire evaluation duration. We use the OpenAI gpt-3.5-turbo-0613 LLM model with a temperature of 0 in all our LLM-DP experiments.
Problem PDDL generation
- LLM-DP uses stored observations W, beliefs B and an LLM to construct different planning problem files in PDDL
- Finally, we convert each likely world state to lists of predicates to interface with the PDDL planner.
- The agent uses a Plan Generator (PG) to solve each problem and obtain a plan.
Example prompt

Results
We contrast the LLM-DP approach with ReAct (LLM-only baseline) from the original implemen- tation by Yao et al. (2023). Since we use a differ- ent backbone LLM model (gpt-3.5-turbo rather than text-davinci-002) than the ReAct base- line for cost purposes, we also reproduce their results using gpt-3.5-turbo and adapt the ReAct prompts to a chat format.
As shown in Table 1, LLM-DP solves Alfworld almost perfectly (96%) compared to our baseline reproduction of ReAct (53%). The LLM-DP can translate the task description into an executable PDDL goal 97% of the time, but sampling reduces the accuracy further when it fails to select a valid set of possible world states – for instance, by sam- pling states where the goal is already satisfied.