[TOC]
- Title: Learning Pessimism for Reinforcement Learning
- Author: Edoardo Cetin et. al.
- Publish Year: 2023
- Review Date: Wed, Mar 1, 2023
- url: https://kclpure.kcl.ac.uk/portal/files/196848783/10977.CetinE.pdf
Summary of paper

Motivation
- Off-policy deep RL algorithms commonly compensate for overestimation bias during temporal difference learning by utilizing pessimistic estimates of the expected target returns
Contribution
- we propose Generalised Pessimism Learning (GPL), a strategy employing a novel learnable penalty to enact such pessimism. In particular
- we propose to learn this penalty alongside the critic with dual TD-learning, a new procedure to estimate and minimise the magnitude of the target returns bias with trivial computational cost.
Some key terms
We attribute recent improvements on RL algs to two main linked advances:
- more expressive models to capture uncertainty
- better strategies to counteract detrimental biases from the learning process.
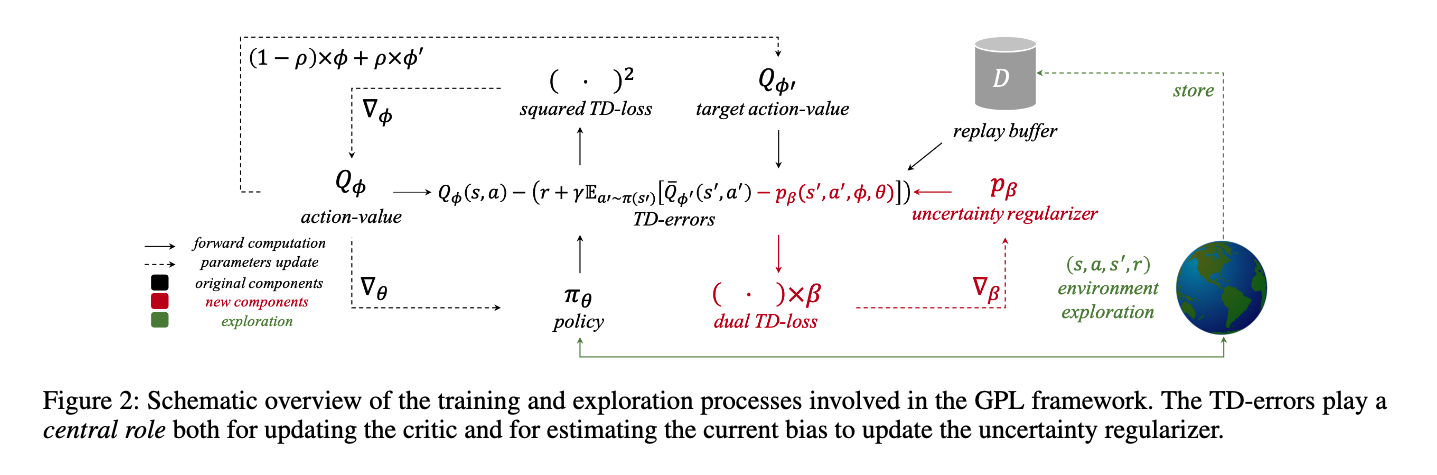
Overestimation problem in Critic model
- Within this process, overestimation bias naturally arises from the maximization performed over the critic’s performance predictions, and consequently, also over the critic’s possible errors
- Solution
- directly model the overestimation bias $p_\beta(s’,a’,\phi,\theta)$
Minor comments
citation
- Sample efficiency and generality are two directions in which reinforcement learning (RL) algorithms are still lacking, yet, they are crucial for tackling complex real-world problems (Mahmood et al. 2018).
Incomprehension
-
I am not so sure why the author only mentioned SAC and neglect other advanced RL algorithms that solves Atari games quite well.
-
