- Title: Attention Over Learned Object Embeddings Enables Complex Visual Reasoning
- Author: David Ding et. al.
- Publish Year: 2021 NeurIPS
- Review Date: Dec 2021
Background info for this paper:
Their paper propose a all-in-one transformer model that is able to answer CLEVRER counterfactual questions with higher accuracy (75.6% vs 46.5%) and less training data (- 40%)
They believe that their model relies on three key aspects:
- self-attention
- soft-discretization
- self-supervised learning
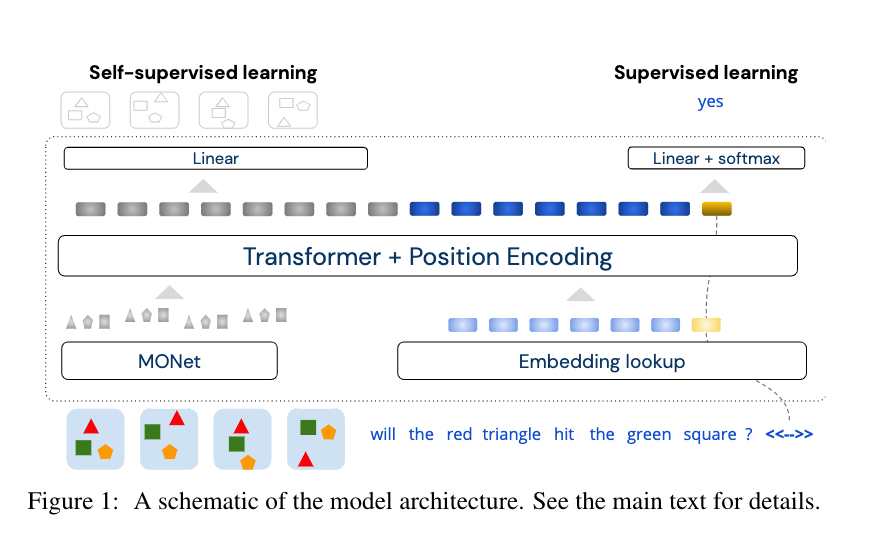
What is self-attention
- Essentially they means they used a Transformer architecture
What is soft-discretization
- given the observation that self-attention module is good at handling discrete entities on a finite sequence, they want to discretise visual information so as to fit into self-attention module
- Given the neuroscience literature that biological visual system infer and exploit the existence of objects rather than spatial or temporal blocks with artificial boundaries, also given that objects are atomic units of newtonian physics interactions, they discretise the visual image on the level of objects
- Essentially this means that they used a object detection module to encode objects in the scene into embeddings
- the embedding $u_{it}$ record the position of object $i$ in local coordinate at time $t$
What is supervised learning
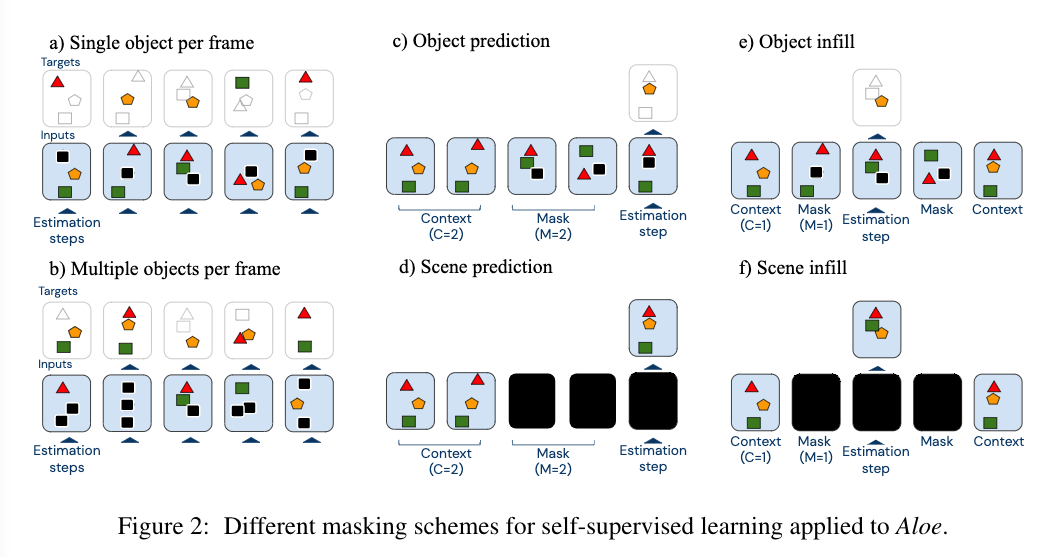
- They mask object embeddings, and train the model to infer the content of the masked object representations using its knowledge of unmasked objects.
- They designed six different masking schemes, which is different from original BERT masking scheme because BERT masking scheme only fits word tokens
What is their result
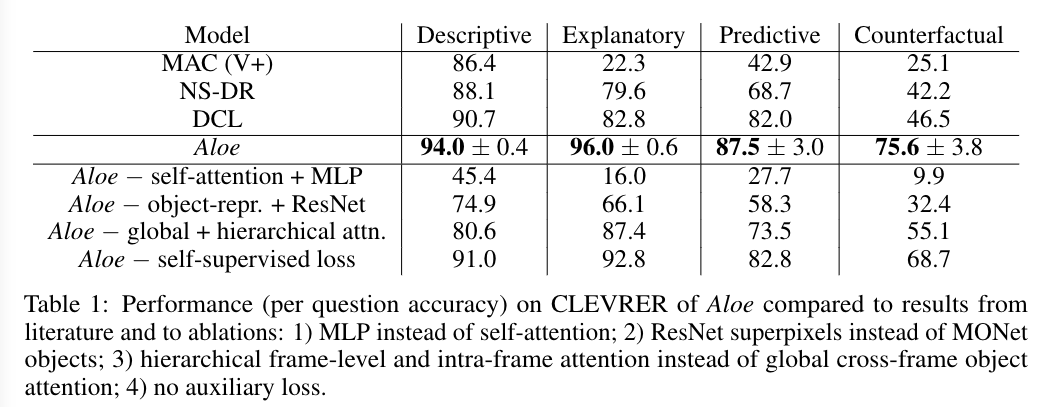
- As we can see, self attention mechanism is super important in their model. In the ablation study, the performance of Aloe model without self-attention will significantly decrease.
- This means that self-attention mechanism is really essential in answering dynamic visual reasoning questions
Their assumptions to break
A guiding motivation for the design of Aloe is the converging evidence for the value of self-attention mechanisms operating on a finite sequences of discrete entities. – The author
Our model relies on three key aspect: 1. Self-attention to effectively integrate information over time 2. … – The author
I do believe that this paper lacks the detail analysis about how attention mechanism solves the reasoning task.
In our basic understanding, attention mechanism would only extract association relationship knowledge. Essentially, attention mechanism was to permit the decoder to utilise the most relevant parts of the input sequence in a flexible manner, by a weighted combination of all of the encoded input vectors, with the most relevant vectors being attributed the highest weights. – Stefania Cristina
There is a conflict between this paper’s result and a common assumption that “statistical machine learning struggles with causality”
There must be more to examine rather than simply saying “Self-attention is good because it effectively integrates information over time”