[TOC]
- Title: Mastering Diverse Domains Through World Models
- Author: Danijar Hafner et. al.
- Publish Year: 10 Jan 2023
- Review Date: Tue, Feb 7, 2023
- url: https://www.youtube.com/watch?v=vfpZu0R1s1Y
Summary of paper

Motivation
- general intelligence requires solving tasks across many domains. Current reinforcement learning algorithms carry this potential but held back by the resources and knowledge required tune them for new task.
Contribution
- we present DreamerV3, a general and scalable algorithm based on world models that outperforms previous approaches across a wide range of domains with fixed hyperparameters.
- we observe favourable scaling properties of DreamerV3, with larger models directly translating to higher data-efficiency and final performance.
Some key terms
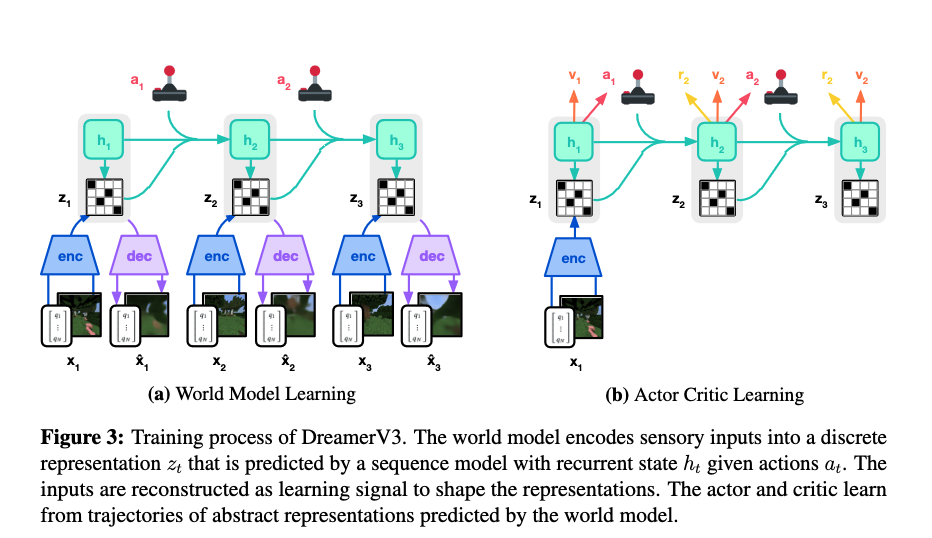
World Model learning
- learn the world dynamics (nothing about value function or reward)
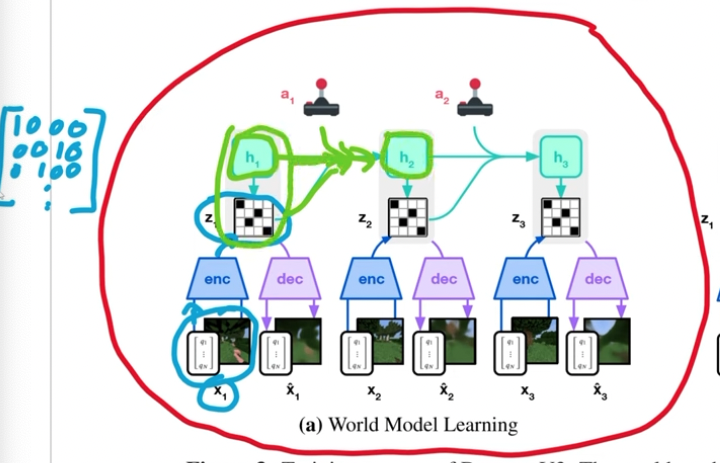
- notes that we want to use hidden state $h_t$ to predict discrete representation $z_t$, it is because later we want to predict the future that there will not no more $x_t$ input.
- it also has a continue predictor to predict whether the world reaches a terminal state.
Some tricks
- normalising the rewards using symlog
- with symlog predictions, there is no need for truncating large rewards, introducing non-stationary through reward normalisation (*Because the reward distribution changes as the agent improves) , or adjusting network weights when new extreme values are detected.
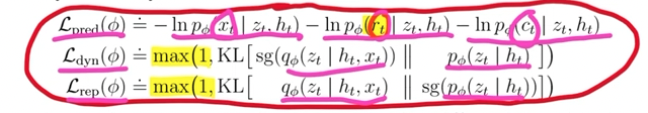
- the $\max$ there, meaning that essentially the dynamic loss and representation loss should not be more important than prediction loss.
- stop gradient is just stop gradient flowing into that parameters.
- critic learning
- The original critic predicts the expected value of a potentially widespread return distributions, which can slow down learning
- we choose a discrete regression approach for leaning the critic based on two hot encoded target
-

Good things about the paper (one paragraph)
- the world model really helps to conquer the game