[TOC]
- Title: DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture of Experts Language Models
- Author: Damai Dai et. al.
- Publish Year: 11 Jan 2024
- Review Date: Sat, Jun 22, 2024
- url: https://arxiv.org/pdf/2401.06066
Summary of paper

Motivation
- conventional MoE architecture like GShard, which avtivate top-k out of N experts, face challenges in ensuring expert specialization, i.e., each expert acquires non-overlapping and focused knowledge,
- in response, we propose DeepSeekMoE architecture towards ultimate expert specialization
Contribution
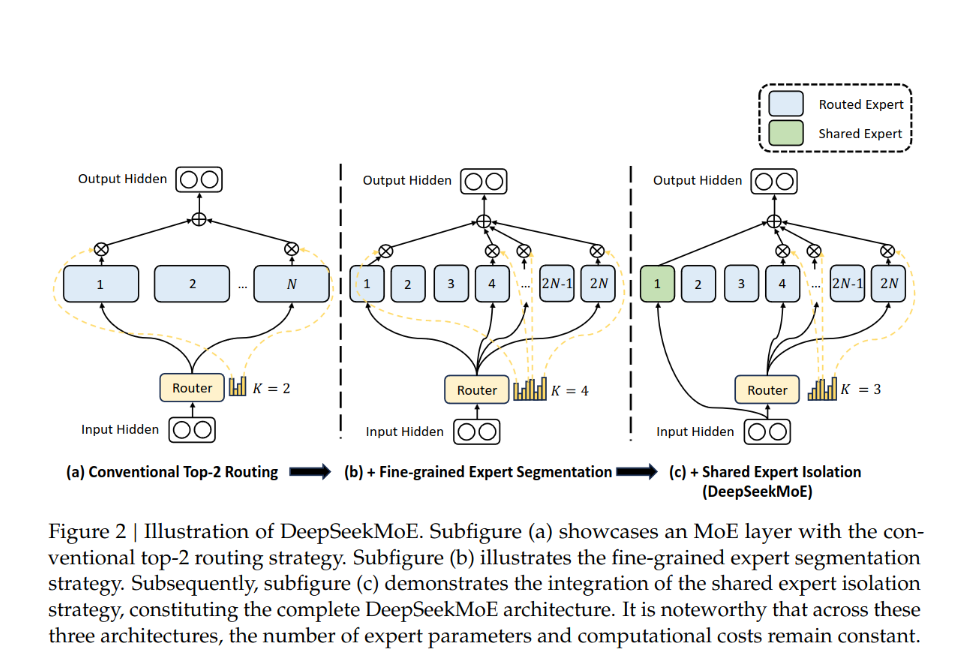
- segmenting expert into mN ones and activating mK from them
- isolating K_s, experts as shared ones, aiming at capturing common knowledge and mitigating redundancy in routed experts
Some key terms
MoE architecture
ref: [1, 2, 3, 4]
[1] R. A. Jacobs, M. I. Jordan, S. J. Nowlan, and G. E. Hinton. Adaptive mixtures of local experts. Neural Computing, 3(1):79–87, 1991. URL https://doi.org/10.1162/neco.1991.3.1. 79.
[2] M. I. Jordan and R. A. Jacobs. Hierarchical mixtures of experts and the EM algorithm. Neural Computing, 6(2):181–214, 1994. URL https://doi.org/10.1162/neco.1994.6.2.181.
[3] N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. V. Le, G. E. Hinton, and J. Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. In 5th International Conference on Learning Representations, ICLR 2017. OpenReview.net, 2017. URL https: //openreview.net/forum?id=B1ckMDqlg.
[4] Dai, Damai, et al. “Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models.” arXiv preprint arXiv:2401.06066 (2024).
Issue of existing MoE
- knowledge hybridity
- limited number of experts (8), thus token will be likely to cover diverse knowledge. the expert will intend to assume vastly different types of knowledge in its parameters, which are hard to utilize simultaneously and also the expert does not focus on a single specialization but instead tries to handle a wide variety of knowledge areas
- knowledge redundancy
- tokens assigned to different experts may require common knowledge. As a result, multiple experts may converge in acquiring shared knowledge in their respective parameters.
Two innovative methods
1. splitting the FFN intermediate hidden dimension
2. shared expert isolation
we isolate certain experts to serve as shared experts that are always activated, aiming at capturing and consolidating common knowledge across varying contexts.

Background

g is the gate, TopK denotes the set comprising K highest affinity score among those calculated for the t-th token and $e^l_i$ is the centroid of the i-th expert in the l-th layer
What is $e^l_i$
In the paper it said $e^l_i$ is the centroid of the i-th expert in the l-th layer,
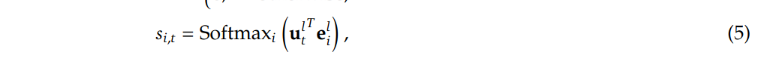
But when we see the code
|
|
The score is calculated as
|
|
|
|
therefore, $e^l_i$ is actually a weight constructed and stored inside the Gate object, it is trainable also.