
[TOC]
- Title: Weak-To-Strong-Generalization: Eliciting Strong Capabilities with Weak Supervision
- Author: Collin Burns et. al.
- Publish Year: 14 Dec 2023
- Review Date: Mon, Jan 29, 2024
- url: arXiv:2312.09390v1
Summary of paper

Motivation
- Superalignment: OPENAI believe that RLHF is essentially use human to supervise the model (RM is trained by human annotation). One day when superhuman models come out, human are no longer to annotate the good / bad of the model’s output. e.g., superhuman model generate a 1M lines complex code and human cannot review it.
- How to do the alignment in for this case?
- thus the research question is can we use a weak teacher model to improve strong student model
Contribution
- they used weak model to generate annotations and fine tune the strong model, they empirically did a lot of experiments
- note: although they use the term teacher and student, the alignment task is not about “teaching”, alignment is to elicit learnt stuffs from strong foundation model (something like finetuning), rather than asking strong model to follow weak teacher model.
Some key terms
Bootstrapping
- Bootstrapping refers to a process where an initial starting point, often basic or minimal, is used to gradually build up more complex or sophisticated systems or solutions. In various contexts, bootstrapping involves self-starting, self-sustaining processes that rely on minimal external resources to initiate growth or development.
approach
- create the weak supervisor
- train a strong student model with weak supervision
- compare train a strong model with ground truth labels as ceiling
limitation of approach
- imitation saliency: today’s mistake made by weak model may not. be the same mistake type when human try to supervise superhuman model
- pretraining leakage: the pretraining dataset contains human supervision implicitly.
- The superhuman model can learn a lot from self-learning. (e.g., AlphaGo)
Performance Gap Recovered Metric
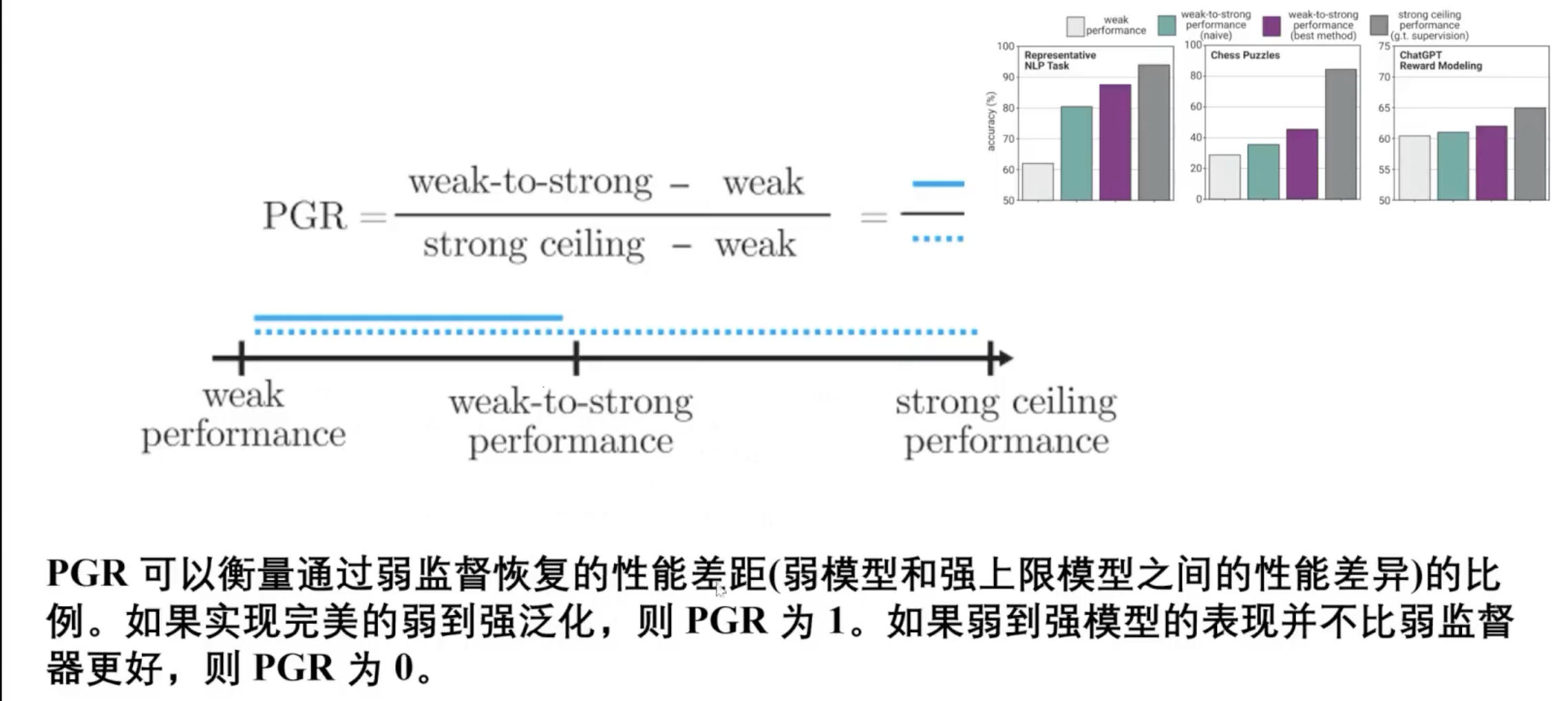
Results
- NLP task
- PGR increases as Student Model’s ability increases
- Weak Student model is able to enhance weak-to-strong supervision even when student model is very weak
- Chess puzzle
- when using weakest student model, PGR get’s to 0
- when Strong model gets stronger, the performance gap recovered gets smaller.
- ChatGPT reward modelling
- Very bad generalisation, PGR cannot pass 20%
Summary
- Direct learning in Strong Student model is the best
- Weak to strong alignment is feasible
- Alignment task is elicitation rather than learning from scratch