[TOC]
- Title: Revisiting Design Choices in Proximal Policy Optimisation
- Author: Chloe Ching-Yun Hsu et. al.
- Publish Year: 23 Sep 2020
- Review Date: Wed, Dec 28, 2022
Summary of paper
Motivation

Contribution
- on discrete action space with sparse high rewards, standard PPO often gets stuck at suboptimal actions. Why analyze the reason fort these failure modes and explain why they are not exposed by standard benchmarks
- In summary, our study suggests that Beta policy parameterization and KL-regularized objectives should be reconsidered for PPO, especially when alternatives improves PPO in all settings.
- The author proved the convergence guarantee for PPO-KL penalty version, as it inherits convergence guarantees of mirror descent for policy families that are closed under mixture
Some key terms
design choices

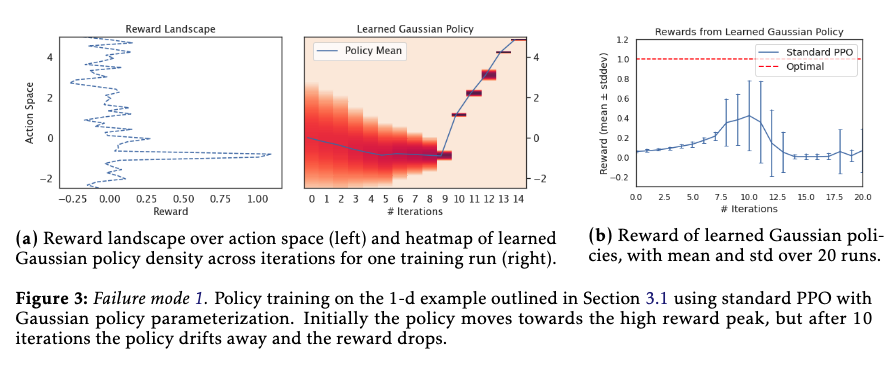
Failure modes of standard PPO
- the clipping mechanism effectively prevents the policy from moving further away once it is outside the trust region, but it does not bound the size of an individual policy update step. this behaviour is particularly problematic if a single reward signal can cause the policy to end up in region with low reward signal.
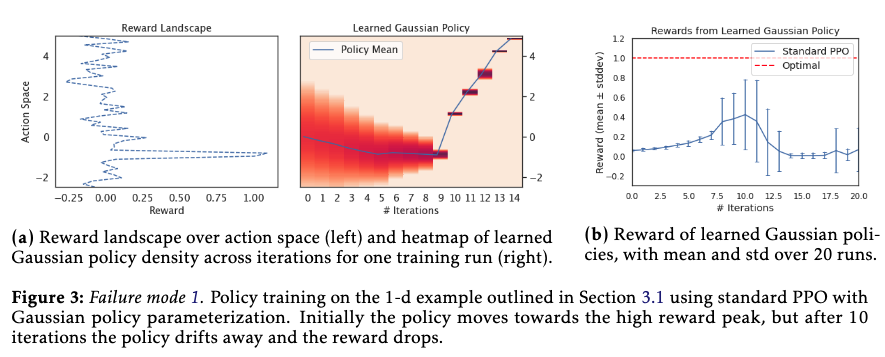
- the abruptly vanishing reward signal outside the interval [-1.0, -0.8] is the main culprit
- reason
- as soon as the $\epsilon$ threshold is exceeded, the clipping mechanism effectively prevents the policy from moving further away in subsequent iterations. However, it does not regularize the individual policy update steps to stay inside the trust region. Thus, if update steps are large, it can cause the policy to move far away from the old policy (the learning rate issue)
Good things about the paper (one paragraph)
Failure mode 2 due to high dimensional discrete action space
- the problem is that when the clipped objective see only the bad actions (reward 0) and the suboptimal actions (reward 0.5) without seeing the optimal action, it tends to increase the probability ratio of the suboptimal actions by (1 + eps), as maximally permitted by the clipping mechanism. After increasing the probability of suboptimal actions in several iteration
- we further note that alternative approaches such as reducing learning rate and increasing batch size can only partially mitigate the issue, while PPO with reverse KL regularisation succeeds on all 20 runs.
- While the high-dimensionality of action spaces is one aspect of the classical exploration-exploitation tradeoff, existing RL research around exploration mostly focuses on continuous, rather than discrete action space.
Advantages of KL-regularization
- KL-regularized PPO enjoys convergence guarantees when the parameterized policy class is closed under mixture

- ref: Liu, Boyi, et al. “Neural proximal/trust region policy optimization attains globally optimal policy.” arXiv preprint arXiv:1906.10306 (2019).
Major comments
Citation
- When the state space S is large, sampling the full action space A on all states would require a batch size of |S| × |A|.
Potential future work
Failure mode 2 might be very relevant to our case