[TOC]
- Title: Diffusion Policy Visuomotor Policy Learning via Action Diffusion
- Author: Cheng Chi et. al.
- Publish Year: 2023
- Review Date: Thu, Mar 9, 2023
- url: https://diffusion-policy.cs.columbia.edu/diffusion_policy_2023.pdf
Summary of paper

Contribution
- introducing a new form of robot visuomotor policy that generates behaviour via a “conditional denoising diffusion process” on robot action space
Some key terms
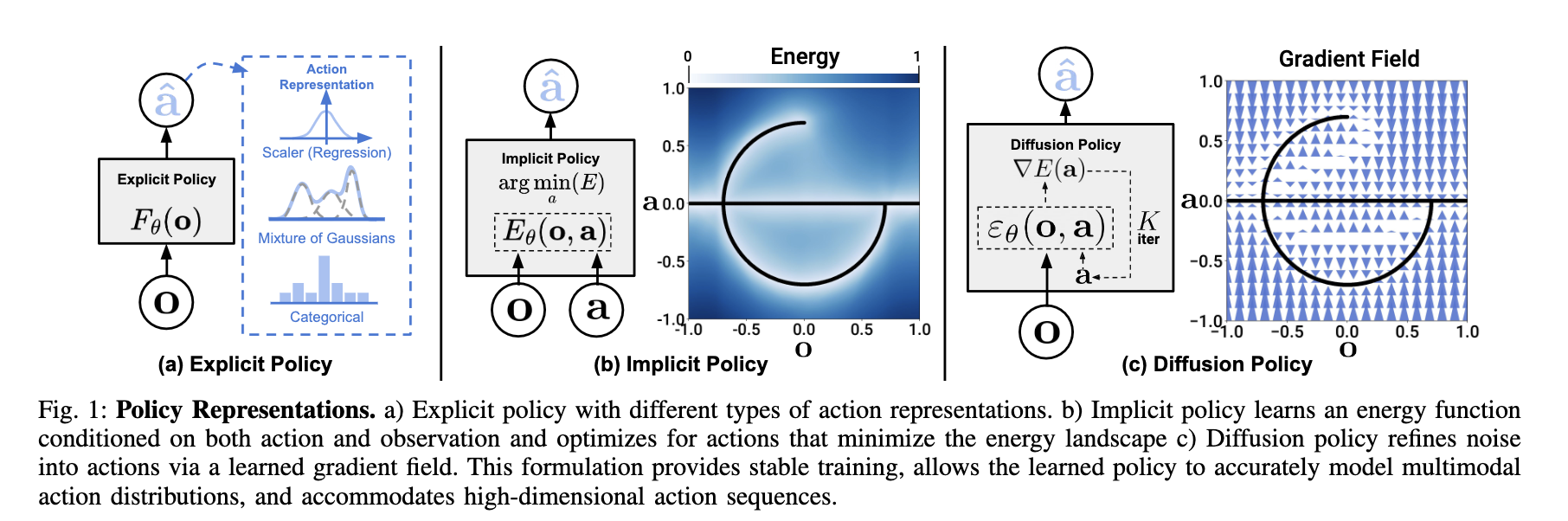
Explicit policy
- learning this is like imitation learning
Implicit policy
- aiming to minimise the estimation of the energy function
- learning this is like a standard reinforcement learning
diffusion policy
- provide a smooth gradient to refining action over each iteration.
Method
Diffusion policy
- in this formulation, instead of directly outputting an action, the policy infers the action-score gradient, conditioned on visual observations, for K demonising iterations
Benefits of this approach
- Expressing multimodal action distributions.
- diffusion policy can express arbitrary normalizable distributions, which includes multimodal action distributions, a well-known challenge for policy learning
- High-dimensional output space
- this property allows the policy to jointly infer a sequence of future actions instead of single-step actions, which is critical for encouraging temporal action consistency
- Stable training
- Training energy-based policy (think about reinforcement learning) often requires negative sampling to estimate an intractable normalisation constant, which is known to cause training instability. Diffusion policy might be more stable.