[TOC]
- Title: Secrets of RLHF in Large Language Models Part II: Reward Modelling
- Author: Binghai Wang et. al.
- Publish Year: 12 Jan 2024
- Review Date: Wed, Jan 24, 2024
- url: arXiv:2401.06080v2
Summary of paper
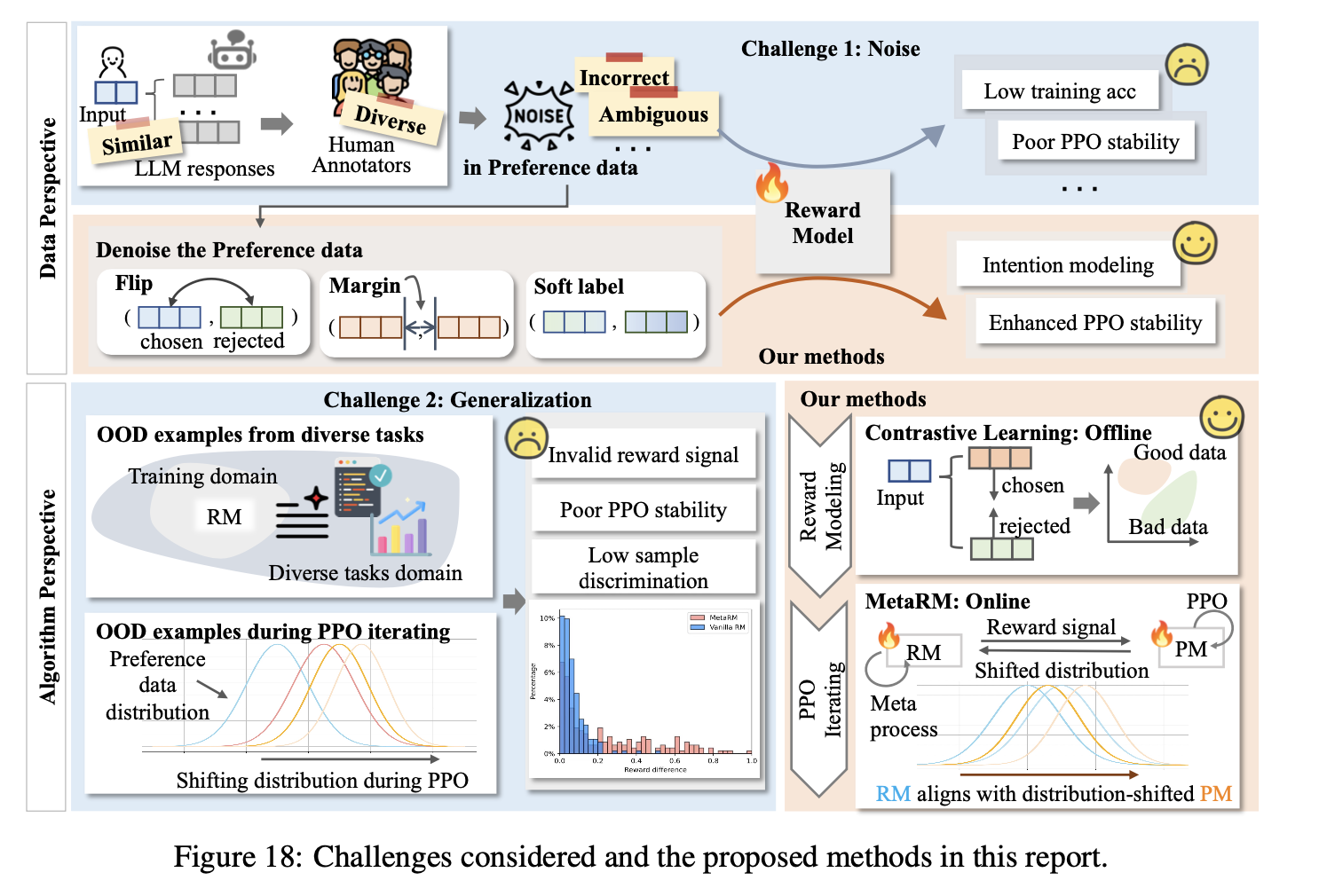
Motivation
- a crucial technology for aligning language models with human values. Two main issues are tackled: (1) Incorrect and ambiguous preference pairs in the dataset hindering reward model accuracy, and (2) Difficulty in generalization for reward models trained on specific distributions.
- a method measuring preference strength within the data is proposed, utilizing a voting mechanism of multiple reward models. Novel techniques are introduced to mitigate the impact of incorrect preferences and leverage high-quality preference data. For the second issue, contrastive learning is introduced to enhance the reward models’ ability to distinguish between chosen and rejected responses, improving generalization.
Some key terms
noisy data
preference strength
flip、margin、soft label for contrastive learning