[TOC]
- Title: Code Llama Open Foundation Model for Code
- Author: Baptiste Roziere et. al. META AI
- Publish Year: 2023
- Review Date: Mon, Oct 16, 2023
- url: https://scontent.fmel13-1.fna.fbcdn.net/v/t39.2365-6/369856151_1754812304950972_1159666448927483931_n.pdf?_nc_cat=107&ccb=1-7&_nc_sid=3c67a6&_nc_ohc=Hcg6QsYJx1wAX_okEZO&_nc_ht=scontent.fmel13-1.fna&oh=00_AfAYtfHJfYeomAQWiMUTRo96iP8d4sZrlIfD_KAeYlYaDQ&oe=6531E8CF
Summary of paper

Motivation
- CODE Llama, support for large input contexts, and zero-shot instruction following ability for programming tasks.
Contribution
- CODE llama reaches SOTA performance among open models on several code benchmarks

Some key terms
-
By training on domain-specific datasets, LLM have proved effective more broadly on applications that require advanced natural language understanding.
-
A prominent use-case is the formal interaction with computer systems, such as program synthesis from natural language specifications, code completion, debugging, and generating documentation
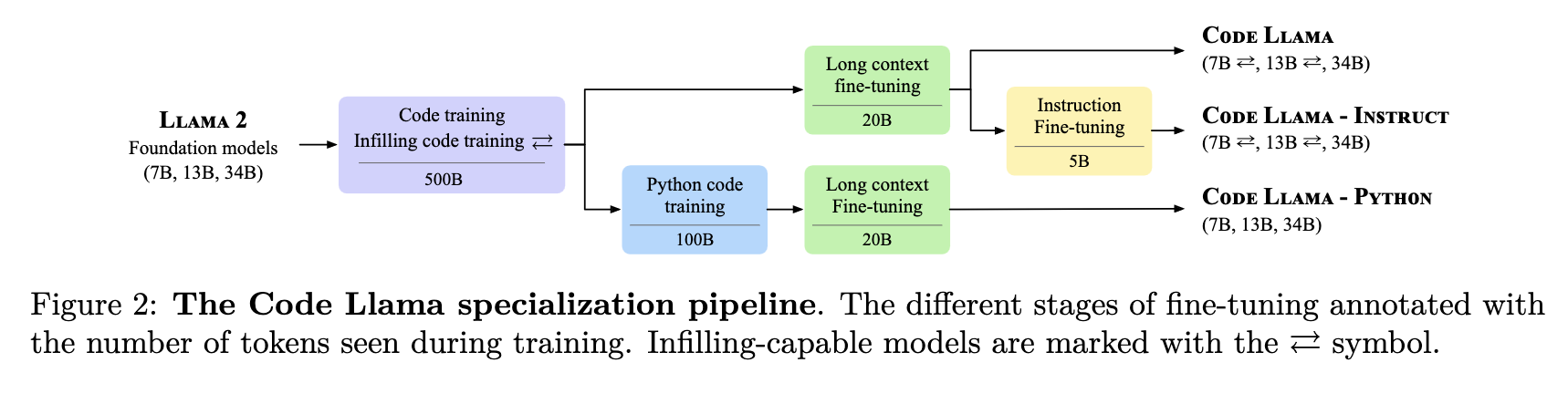
code-training from foundation models
- Our comparison (Section 3.4.1) shows that initializing our model with Llama 2 outperforms the same architecture trained on code only for a given budget.
infilling

- code infilling is the task of predicting the missing part of a program given a surrounding context. Applications include code completion at the cursor’s position in code IDEs, type inference and generation of in-code documentation.
instruction fine-tuning

Dataset
- CODE LLAMA is trained predominantly on a near-deduplicated dataset of publicly available code.
- we also source 8% of our sample data from natural language dataset related to code.
- Preliminary experiments suggested that adding batches sampled from our natural language dataset improves the performance of our models on MBPP.
prefix-suffix-middle (PSM)
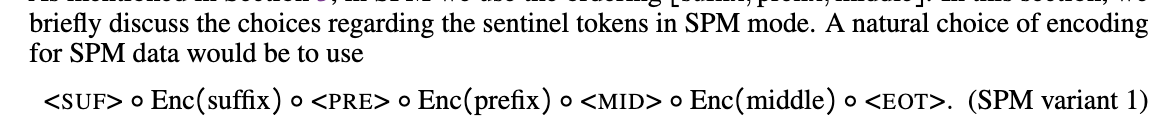

- essentially, fill-in-the-middle(FIM) is implemented such that, with a simple modification to training data and without changing the model architecture, causal docoder-based autoregressive (AR) language models can learn infilling without compromising their normal left-to-right generative capability.
self-instruct
- instead of human feedback, we use execution feedback to select data to train our instruct model

Major comments
NO information about back-translation objective in this paper.