
The study in this field is very messy I should say, a lot of researchers coming from different background and most of them try to publish their own embodied environments and baseline models. There is a lack of systematic study in this field. Most importantly, their model are really difficult to reproduce. In fact, there is no standard phrase for this research field. Some people call it instruction following with LM, some people call it language grounding in embodied environments, some people call it instruction-following with RL and all the papers in this area did not even try to reproduce other’s work and compare with each other. So, I want to say be careful to enter this area.
Survey paper: A Survey of Reinforcement Learning Informed by Natural Language
https://arxiv.org/pdf/1906.03926
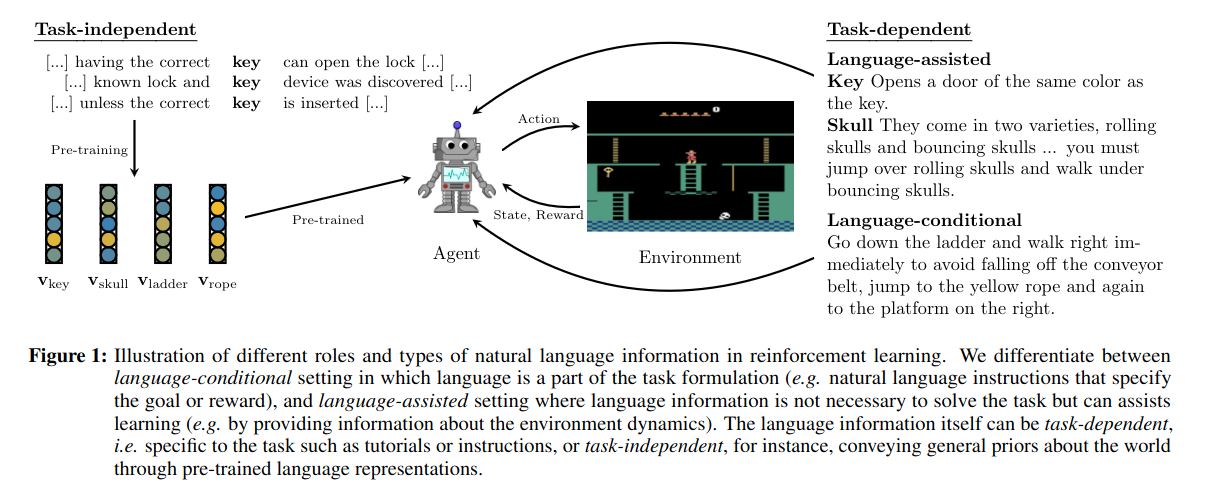
TRUE KNOWLEDGE COMES FROM PRACTICE: ALIGNING LLMS WITH EMBODIED ENVIRONMENTS VIA REINFORCEMENT LEARNING
https://arxiv.org/pdf/2401.14151
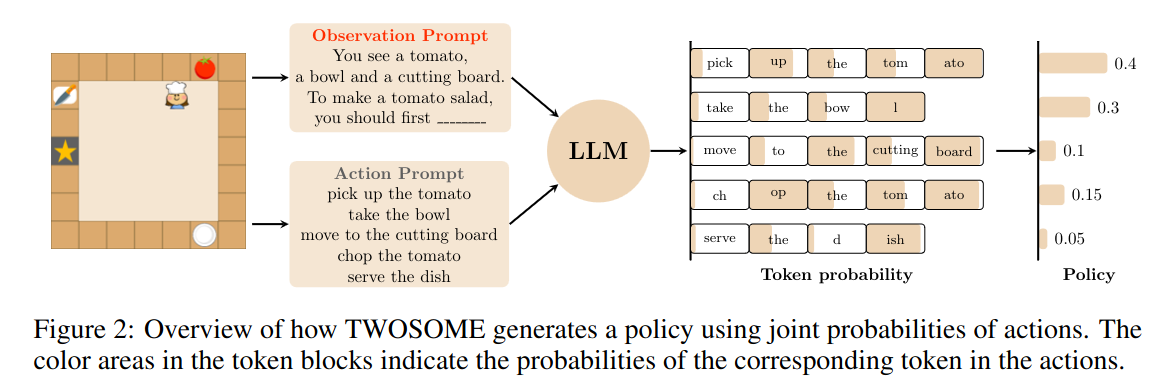
LARGE LANGUAGE MODELS AS GENERALIZABLE POLICIES FOR EMBODIED TASKS
https://arxiv.org/pdf/2310.17722
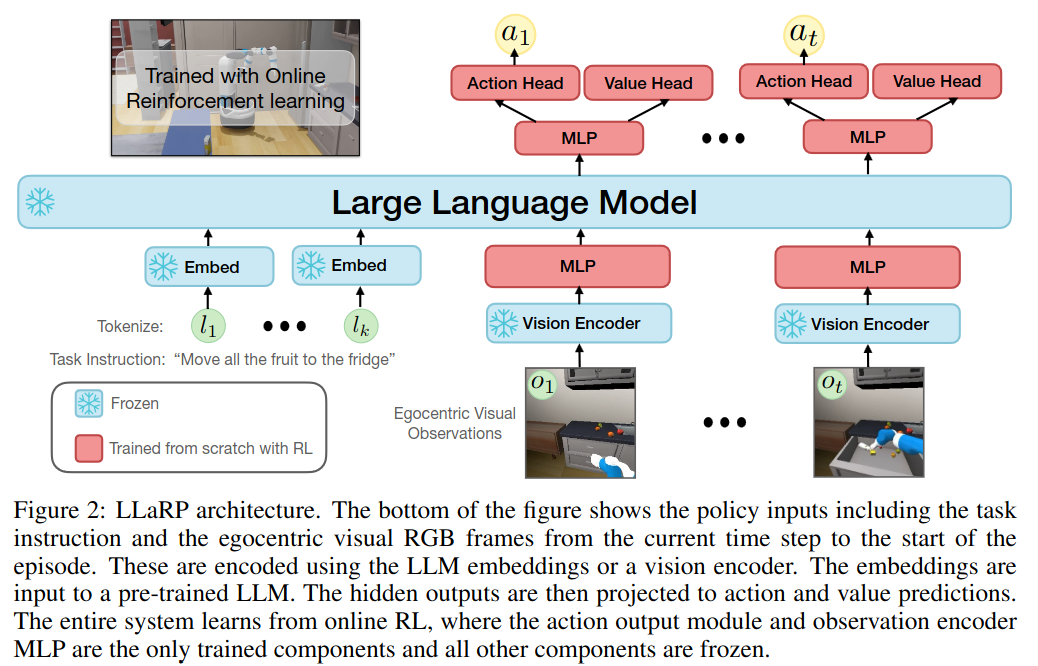
To our knowledge, no prior work demonstrates that LLMs can be used as vision-language policies in online RL problems to improve generalization.
That adapter layer is also used in Do Embodied Agents Dream of Pixelated Sheep: Embodied Decision Making using Language Guided World Modelling. ICML 2023: 26311-26325
This is the statement made by the authors.
The reviewer call it as adapting large language models to embodied visual tasks - particularly in online reinforcement learning setting
https://openreview.net/forum?id=u6imHU4Ebu
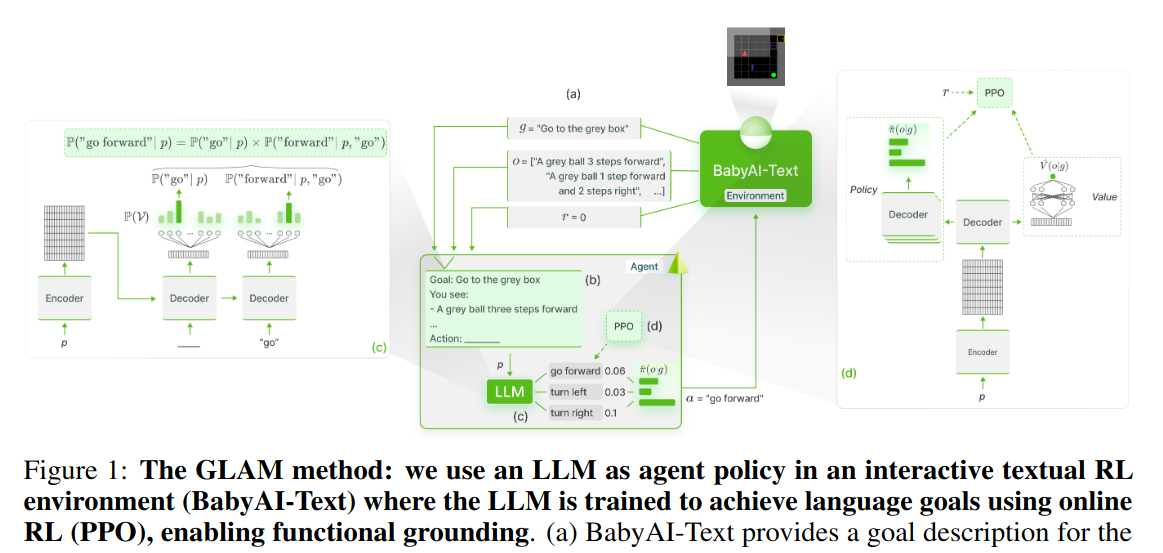
Grounding Large Language Models in Interactive Environments with Online Reinforcement Learning
https://arxiv.org/pdf/2302.02662v4
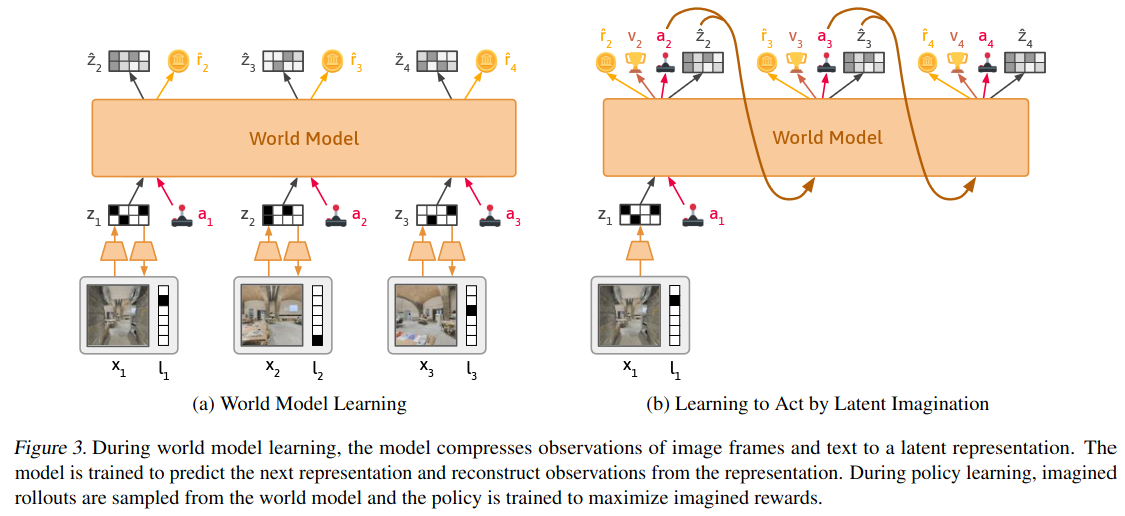
Learning to Model the World With Language *
https://arxiv.org/pdf/2308.01399
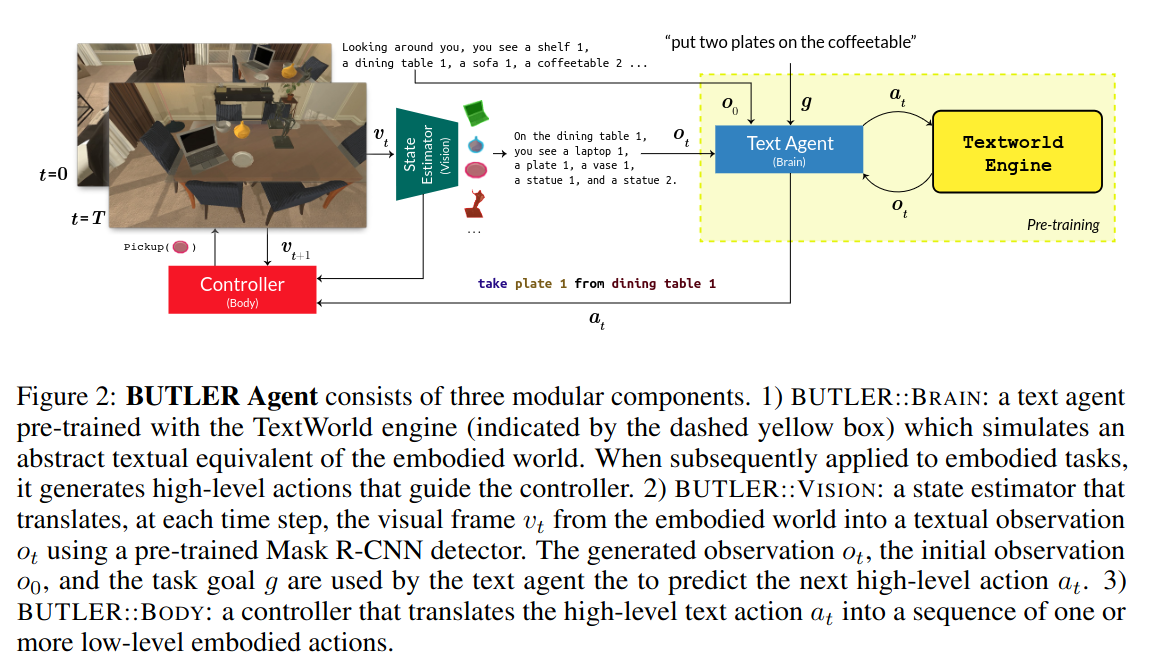
ALFWORLD: ALIGNING TEXT AND EMBODIED ENVIRONMENTS FOR INTERACTIVE LEARNING
https://arxiv.org/pdf/2010.03768
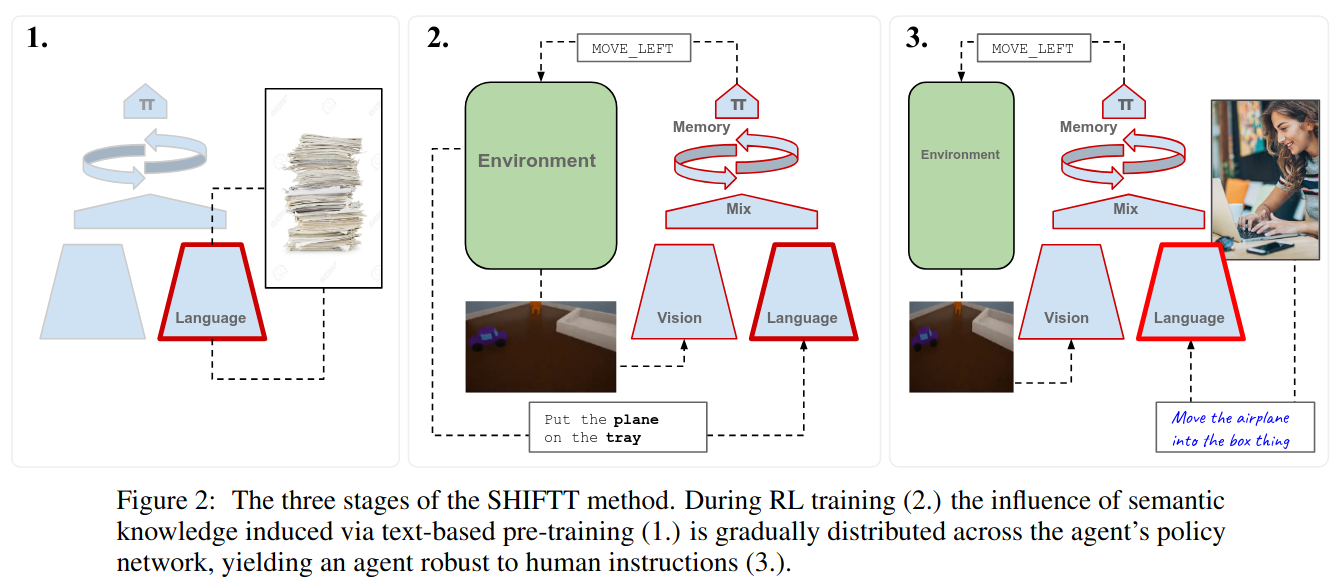
Human Instruction-Following with Deep Reinforcement Learning via Transfer-Learning from Text
https://arxiv.org/pdf/2005.09382
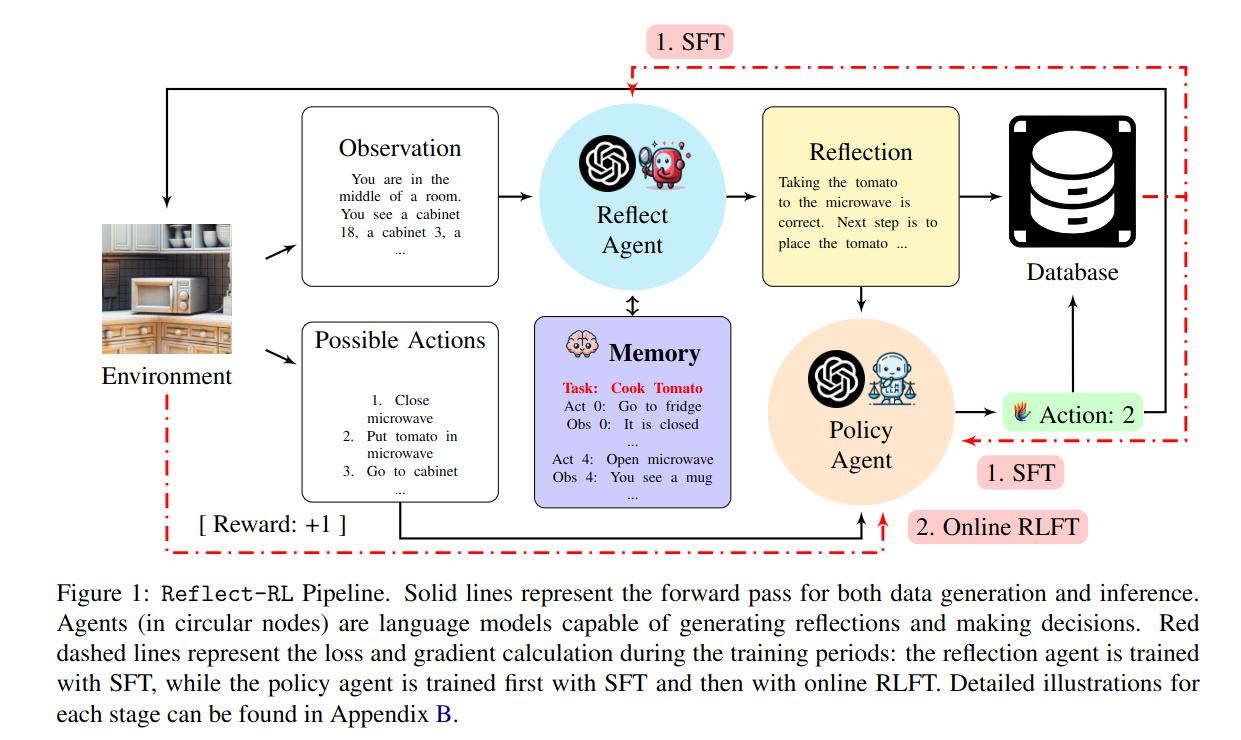
Reflect-RL: Two-Player Online RL Fine-Tuning for LMs
https://arxiv.org/pdf/2402.12621
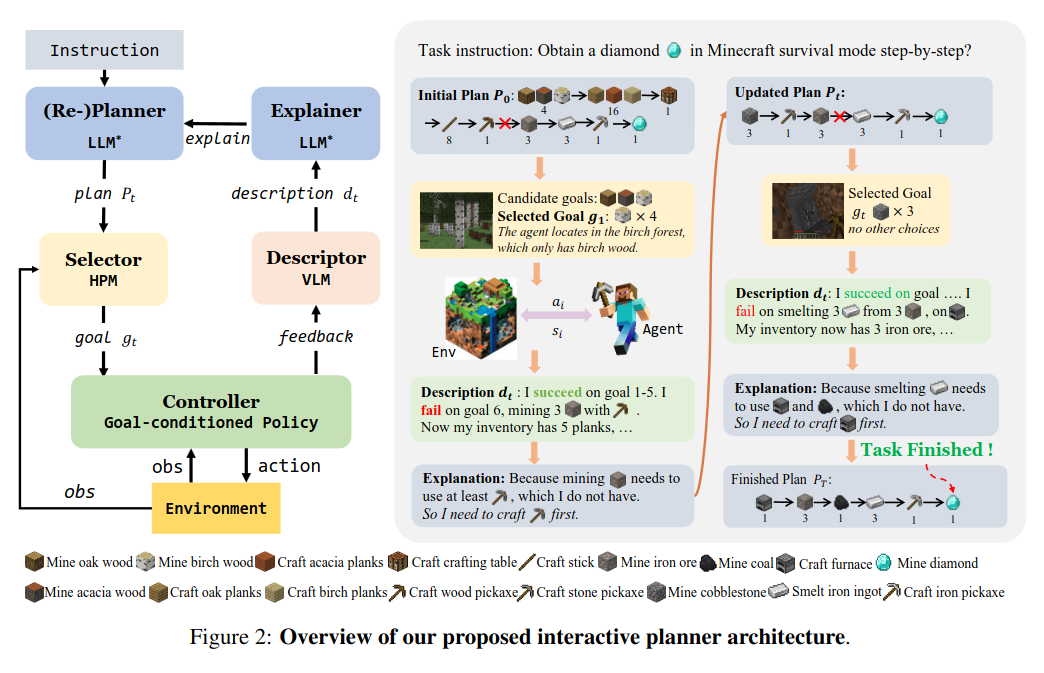
Describe, Explain, Plan and Select: Interactive Planning with Large Language Models Enables Open-World Multi-Task Agents
https://arxiv.org/pdf/2302.01560
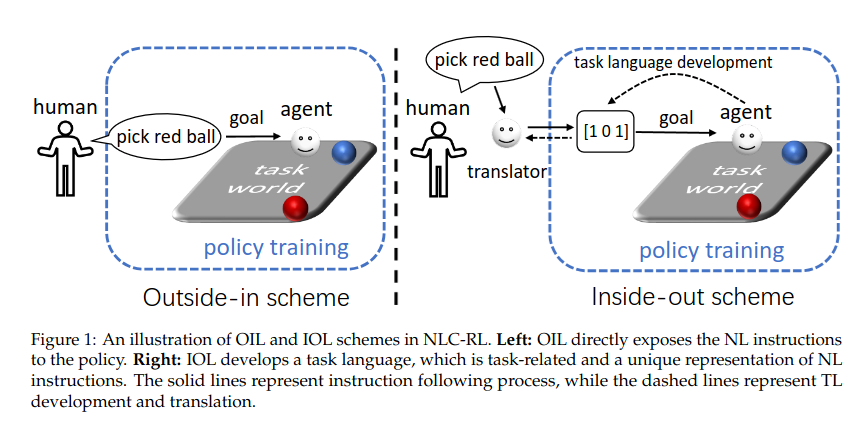
Natural Language-conditioned Reinforcement Learning with Inside-out Task Language Development and Translation
https://arxiv.org/pdf/2302.09368
Do Embodied Agents Dream of Pixelated Sheep?: Embodied Decision Making using Language Guided World Modelling
https://arxiv.org/abs/2301.12050
This also belongs to Plan first and then train policy but this time it is modular policy.
ICML 2023
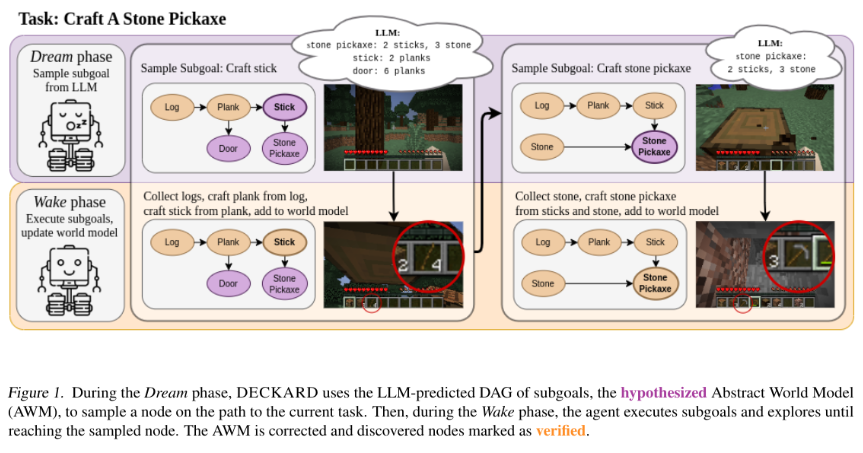
A nice thing for their policy model is that they use an adapter to the original decision transformer policy model to train their own fine-tuned policy.

Relevant but in Robotics field, but they are using offline data to train low-level control policy and they are effective
PaLM-E https://arxiv.org/abs/2303.03378 and SayCan https://say-can.github.io/assets/palm_saycan.pdf
SayCan, CodeAsPolicy and ProgPrompt are zero-shot applications of LLMs that require describing the environment in text
PaLM-E are offline: they are given 130,000 human teleoperated demonstrations collected over almost 2 years as training data [2,3]
Both try to separate into high-level plan action and then low-level control action
Palm-E

Saycan

