
Fine-tuning Reinforcement Learning Models is Secretly a Forgetting Mitigation Problem
https://arxiv.org/pdf/2402.02868v3
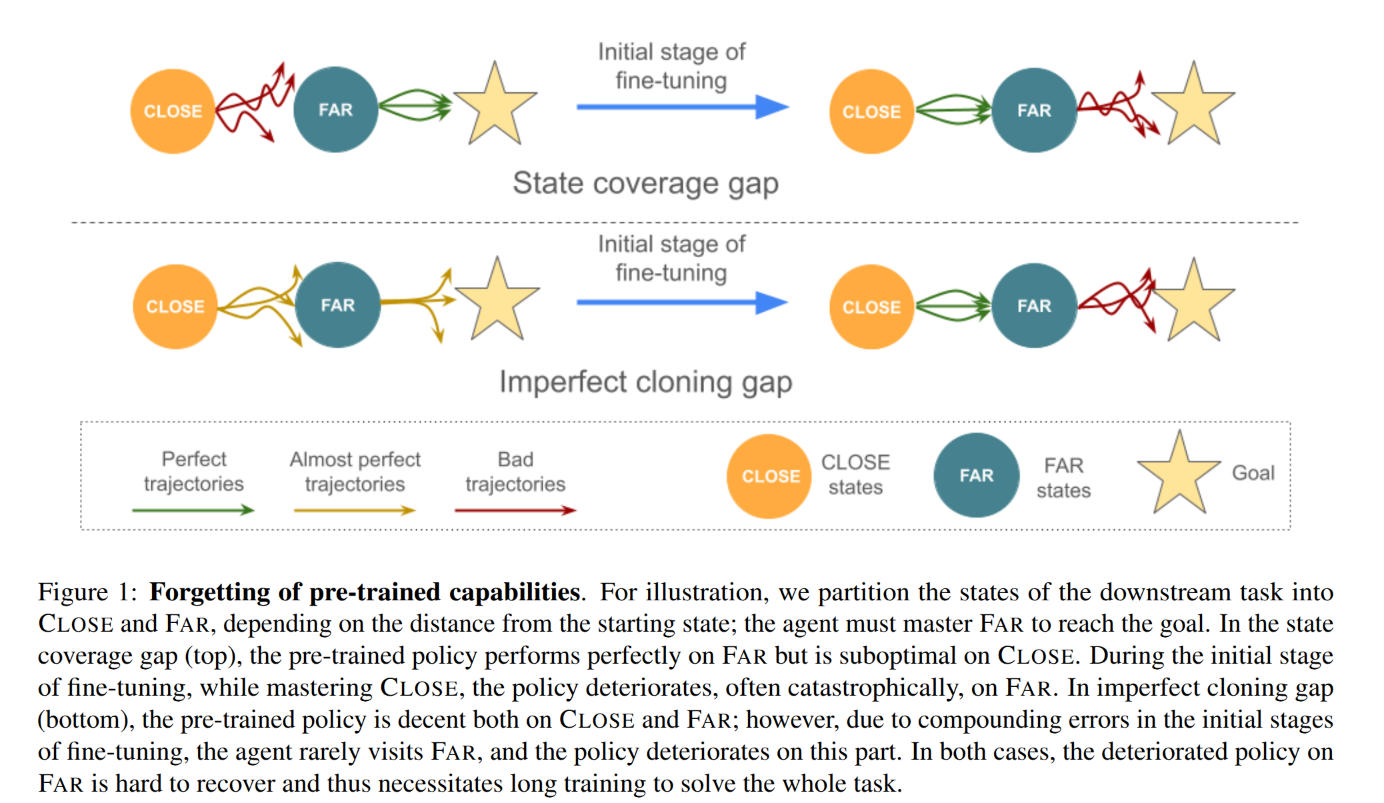

Lifelong Reinforcement Learning with Modulating Masks
https://arxiv.org/pdf/2212.11110
This has some connection with LLM + adapter Policy model.
