[TOC]
- Title: A Picture Is Worth a Thousand Words Language Models Plan From Pixels
- Author: Anthony Liu et.al.
- Publish Year: 16 Mar 2023
- Review Date: Mon, Apr 3, 2023
- url: https://arxiv.org/pdf/2303.09031v1.pdf
Summary of paper

Motivation
- planning is a important capability of AI that perform long-horizon tasks in real-world environments.
- prior PLM based approaches for planning either assume observations are available in the form of text, reason about plans from the instruction alone, or incorporate information about the visual environment in limited ways.
Contribution
- in contrast, we show that PLMs can accurately plan even when observations are directly encoded as input prompts for the PLM
Some key terms
why we need the ability to reason about plans
- The ability to reason about plans is critical for performing long-horizon tasks (Erol, 1996; Sohn et al.,2018; Sharma et al., 2022), compositional generalisation (Corona et al., 2021) and generalisation to unseen tasks and environments (Shridhar et al.,2020).
visually grounded planning with PLMs
- the ability to adapt plans based on interaction and visual feedback from the environment.
multimodal embedding
- directly inserting visual observations as PLM input embeddings
- the visual encoder and PLM are jointly trained for the target task, an approach we call Visual Prompt Planning (VP^2)
- by teaching the PLM to user observations for planning in an end to end manner, we remove the dependency on external data such as captions and affordability information that was used in prior work.
Visual Prompt Planning
- if goal description, actions and observations are available in the form of discrete token sequences, predicting the next action is similar to a language modelling task and a PLM can be fine-tuned for next action prediction
- maximise $\log p_{LM}(a_t | cxt_{t})$, where $cxt_{t} = concat(g, o_1, a_1, o_2, a_2,…, a_{t-1}, o_t)$.
- However, observations may not be available in the form of text or discrete tokens in practice and we attempt to tackle this scenario
- observation encoder, we need to encode observations (image rather than video in this case) into a sequence of token
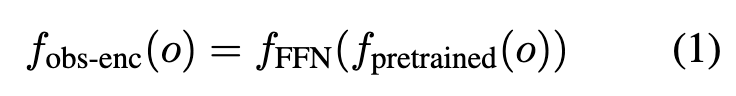
- and we have an end to end training objective
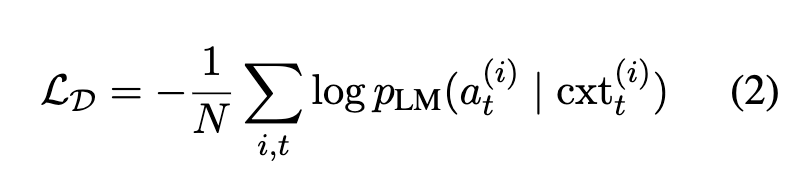
- this is for offline RL
Potential future work
- this direct encoding visual observations into prompt is very convenient.