
[TOC]
- Title: Reward Delay Attacks on Deep Reinforcement Learning
- Author: Anindya Sarkar et. al.
- Publish Year: 8 Sep 2022
- Review Date: Mon, Dec 26, 2022
Summary of paper
Motivation
- we present novel attacks targeting Q-learning that exploit a vulnerability entailed by this assumption by delaying the reward signal for a limited time period.
- We evaluate the efficacy of the proposed attacks through a series of experiments.
Contribution
- our first observation is that reward-delay attacks are extremely effective when the goal for the adversarial is simply to minimise reward.
- we find that some mitigation method remains insufficient to ensure robustness to attacks that delay, but preserve the order, of rewards.
Conclusion
- Our results thus suggest that even a relatively short delay in the reward signal can lead DQN learning to be entirely ineffective.
- Our empirical findings suggest that it is possible to induce a sub-optimal policy by strategically reshuffling the true reward sequence. Even randomly shuffling reward within relatively short time intervals is already sufficient to cause learning failure.
- Reward delay attack also has a disastrous effect on DQN learning, implying that the DRL process can be easily disrupted when reward channel is corrupted.
Some key terms
Synchrony
- Our attack exploits a common assumption of synchrony in reinforcement learning algorithms. Specifically, we assume that the adversary can delay rewards a bounded number of time steps (for example, by scheduling tasks computing a reward at time t after the task computing a reward at time t+k for some integer k >= 0)
reward shifting attacks
- an adversary can only drop rewards, or shift these a bounded number of steps into the future.
untargeted attack
- simply aim to minimise the reward obtained by the learned policy
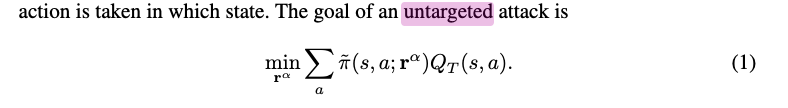
Untargeted reward delay attacks
- we investigate the efficacy of the untargeted reward delay attacks as we change $\delta$, the maximum delay we can add to a reward (i.e., the maximum we can shift reward back in time relative to the rest of DQN update information)
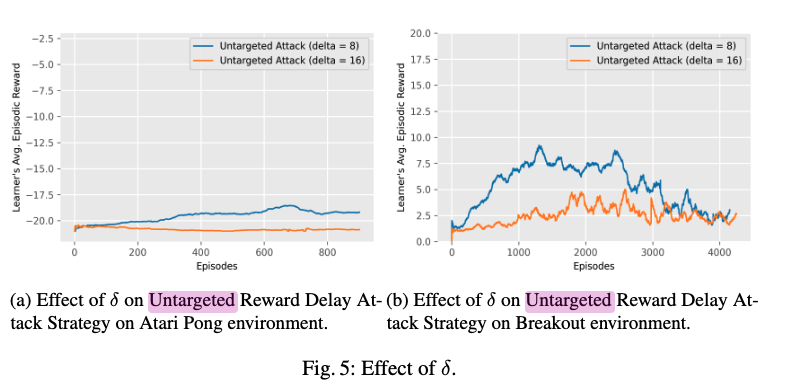
- what is surprising, however, is that this improvement is extremely slight, even though we doubled the amount of time the reward can be delayed.
- Our results thus suggest that even a relatively short delay in the reward signal can lead DQN learning to be entirely ineffective.