[TOC]
- Title: Knowledge Is a Region in Weight Space for Fine Tuned Language Model
- Author: Almog Gueta et. al.
- Publish Year: 12 Feb 2023
- Review Date: Wed, Mar 1, 2023
- url: https://arxiv.org/pdf/2302.04863.pdf
Summary of paper

Motivation
- relatively little is known a bout the relationships between different models, especially those trained or tested on different datasets.
Contribution
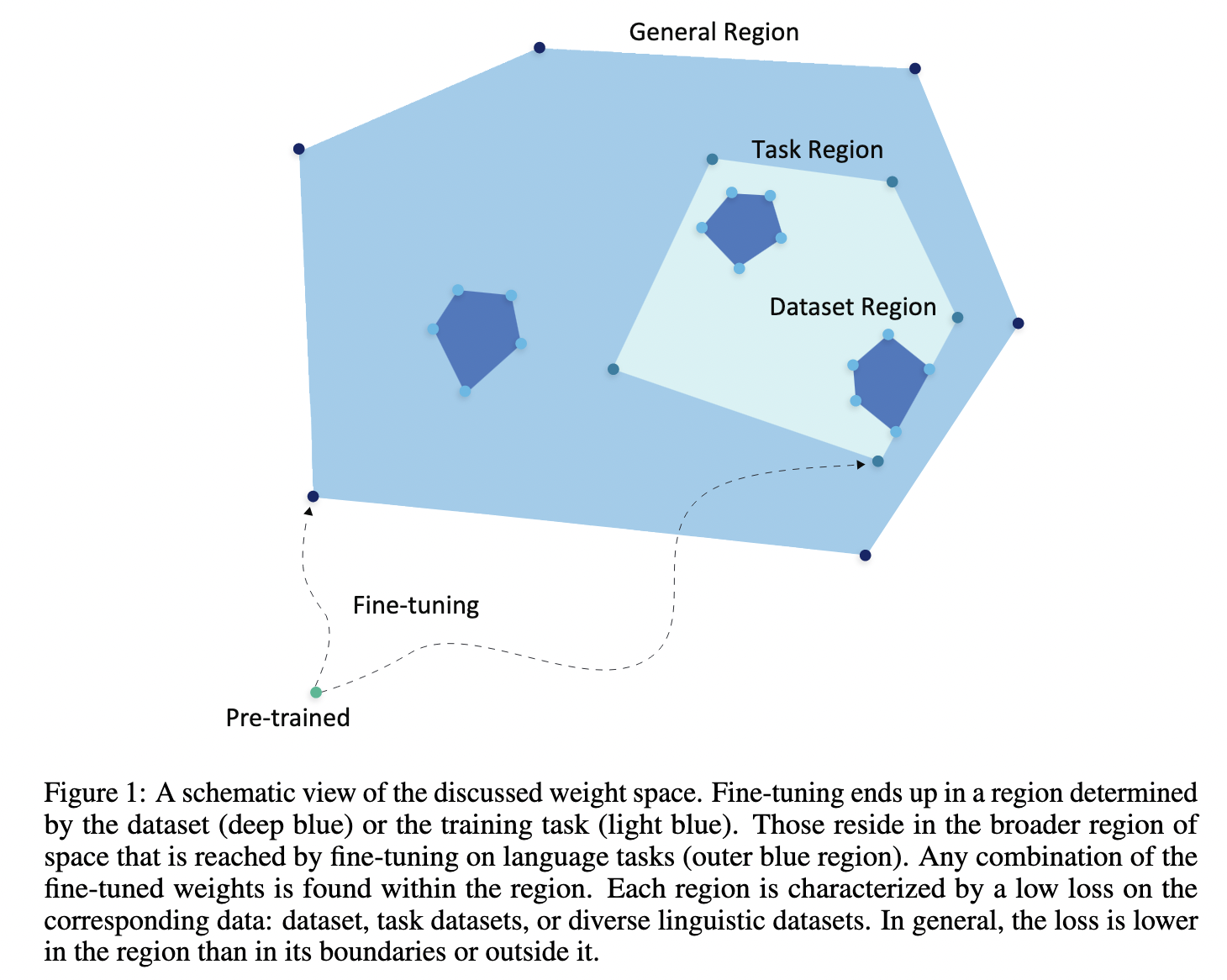
- we demonstrate that fine-tuned models that were optimized for high performance, reside in well-defined regions in weight space, and vice versa
- language models that have been fine-tuned on the same dataset form a tight cluster in the same weight space and that models fine-tuned on different datasets from the same underlying task form a looser cluster.
- traversing around the region between the models reaches new models that perform comparably or even better than models found via fine-tuning
- Our findings demonstrate that a model positioned between two similar models can acquire the knowledge of both. We leverage this finding and design a method to pick a better model for efficient fine-tuning.
more findings
- we show that after a pre-trained model is fine-tuned on similar datasets, the resulting fine-tuned models are close to each other in the weight space.
- models fine-tuned on the sae data are closer to each other than to to other models
- models that were fine-tuned on the same task also cluster together
- models fine-tuned on language tasks are not spread around the pre-trained space arbitrarily but rather correspond to a constrained region in weight space
Some key terms
rather than fine-tuning
- Notably, such points in weight space might not necessarily be reached via fine-tuning, but rather via spatial transformation.
points on a line between the two points representing two models fine-tuned on the same dataset
- we find that points on a line between the two points representing two models fine-tuned on the same dataset attain similar or even lower loss than the two individual models.
empirical findings
- suggesting, for example, that the best models may not lie at the edges of the region, but rather closer to its center, while fine-tuning often yields models at the edge of the region
- motivated by these findings, we demonstrate that a model created by averaging the weights of fine-tuned models from the same region outperforms the pre-trained model on a variety of tasks after subsequent fine-tuning.
Comparing models
- comparing loss difference is the core idea but the loss of a given model is often incomparable across datasets or tasks
- to define a loss that is comparable across models, we first adopt the typical perspective that the model $f_\theta$ consist of a representation encoder $f_w$ followed by a task-specific $f_\phi$, i.e., $f_\theta = f_\phi \circ f_w$
- to calculate the loss we do the following
- first, remove any existing masked language modeling layers or classification heads and replace them with a new randomly initialised classification head. This leaves the rest of the weights i.e., the encoder $f_w$ fixed.
- We then perform linear probing i.e., we train only the new classification head on a desired target data and its label
- Lastly, we pass the test data through the model and report the loss with respect to the label.
Projection by t-SNE
- t-distributed stochastic neighbor embedding (t-SNE) is a statistical method for visualising high-dimensional data by giving each datapoint a location in a two-or three dimensional map.