[TOC]
- Title: Segment Anything
- Author: Alexander Kirillov et. al.
- Publish Year: 5 Apr 2023
- Review Date: Sun, May 21, 2023
- url: https://arxiv.org/pdf/2304.02643.pdf
Summary of paper

Motivation
-
we introduce the segment anything project: a new task, model and dataset for image segmentation.
-
Using the model in a data collection loop, we built the largest segmentation dataset to date.
Contribution
- the model is designed and trained to be promptable, so it can transfer zero-shot to new images distributions and tasks.
background
- CLIP and ALIGN use contrastive learning to train text and image encoders that align the two modalities.
goal of the authors
- build a foundation model for image segmentation
- seek to develop a promptable model and pre-trained it on a broad dataset
Some key terms
the plan hinges on three components
- task, model, and data
- what task will enable zero-shot generalisation
- what is the corresponding model architecture
- what data can power this task and model
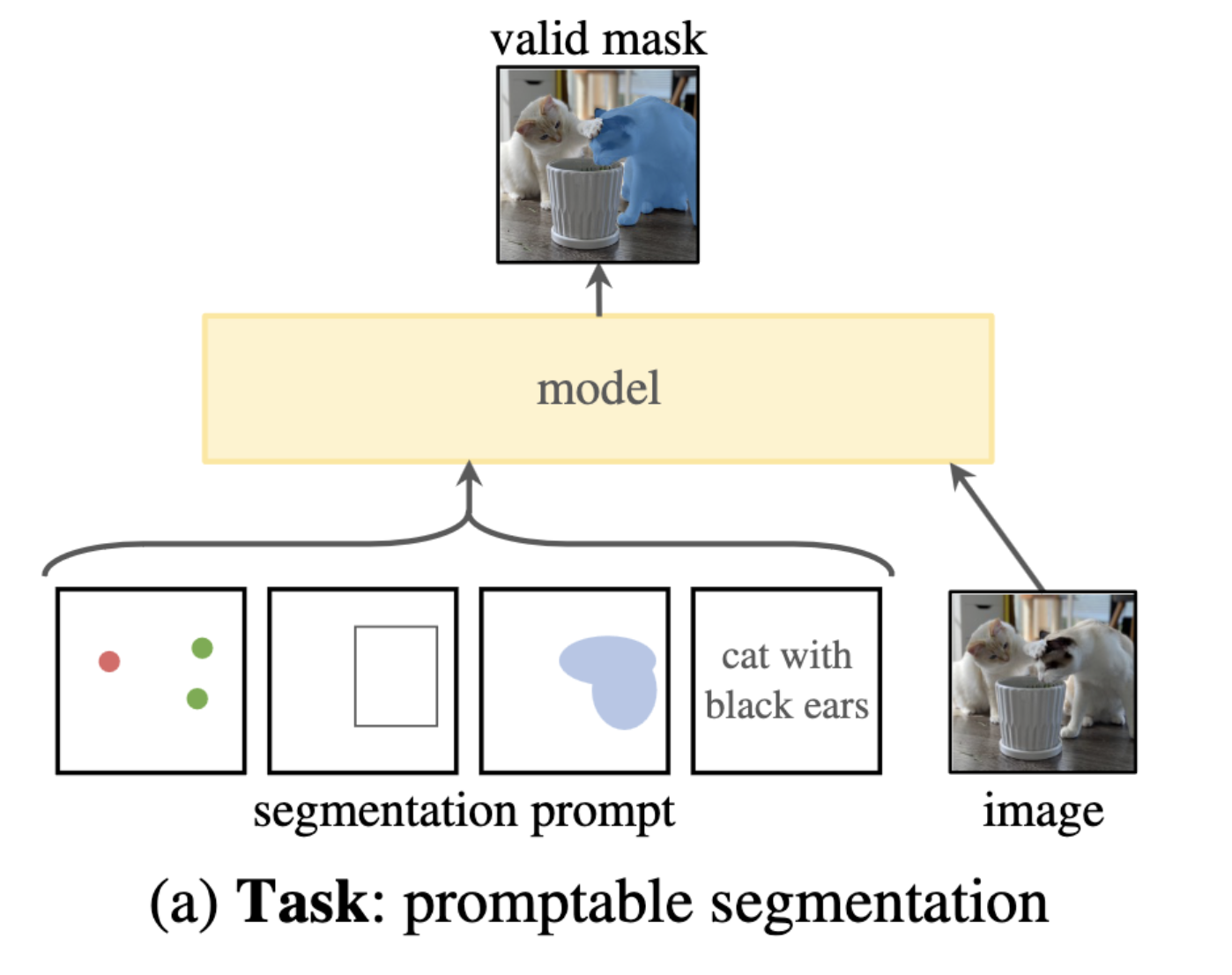
promptable segmentation mask
- a prompt simply specify what to segment in an image
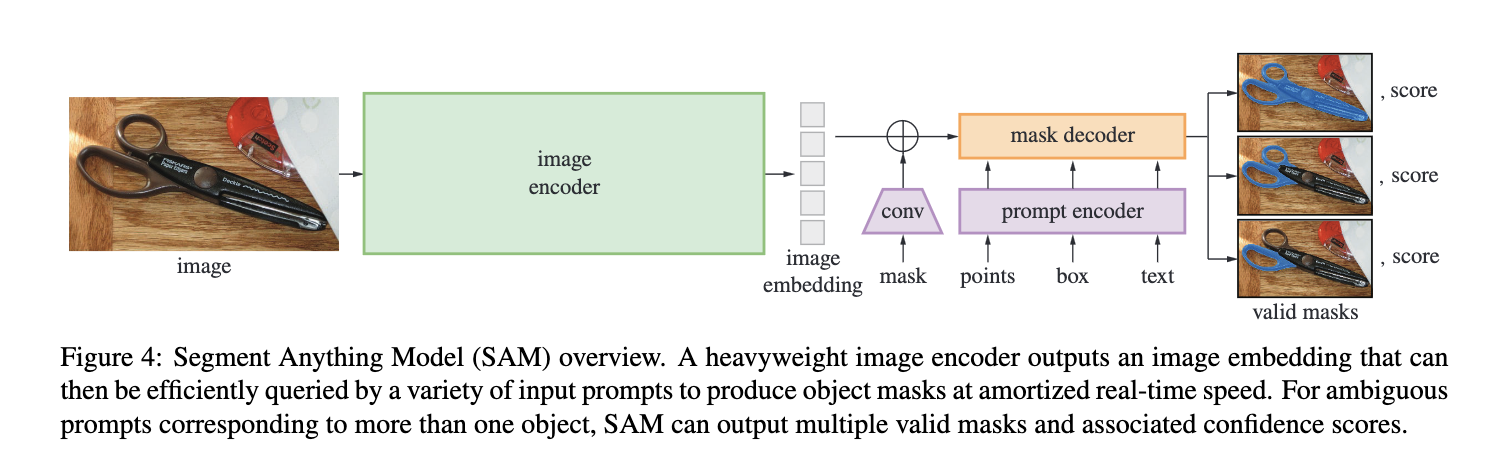
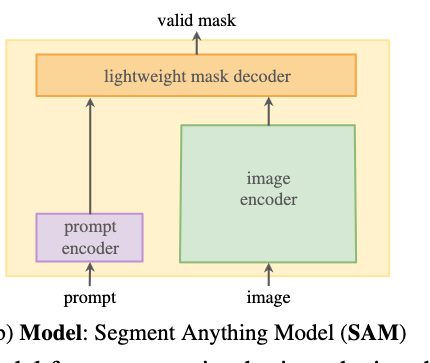
model for the promptable segmentation task
- the model must support flexible prompts
- and must be ambiguity-aware
Segment Anything task
- we start by translating the idea of a prompt from NLP to segmentation, where a prompt can be a set of foreground /background points, a rough box or mask, free-form text
- the requirement of a valid mask simply means that even when a prompt is ambiguous and could refer to multiple objects, the output should be a reasonable mask for at least one of those objects.
- this is similar to expecting a language model to output a coherent response to an ambiguous prompt.
interactive segmentation
- interactive segmentation is a technique for picking objects of interest in images according to users’ input interactions.
Resolving ambiguity
- With one output, the model will average multiple valid masks if given an ambiguous prompt. To address this, we modify the model to predict multiple output masks for a single prompt
- this require human annotation though
- during training, we backprop only minimum loss over masks.
Potential future work
- linear classifier might be a good way to map output tokens to segmentations.
- tackle ambiguity issue might be helpful