[TOC]
- Title: Language Reward Modulation for Pretraining Reinforcement Learning
- Author: Ademi Adeniji et. al.
- Publish Year: ICLR 2023 reject
- Review Date: Thu, May 9, 2024
- url: https://openreview.net/forum?id=SWRFC2EupO
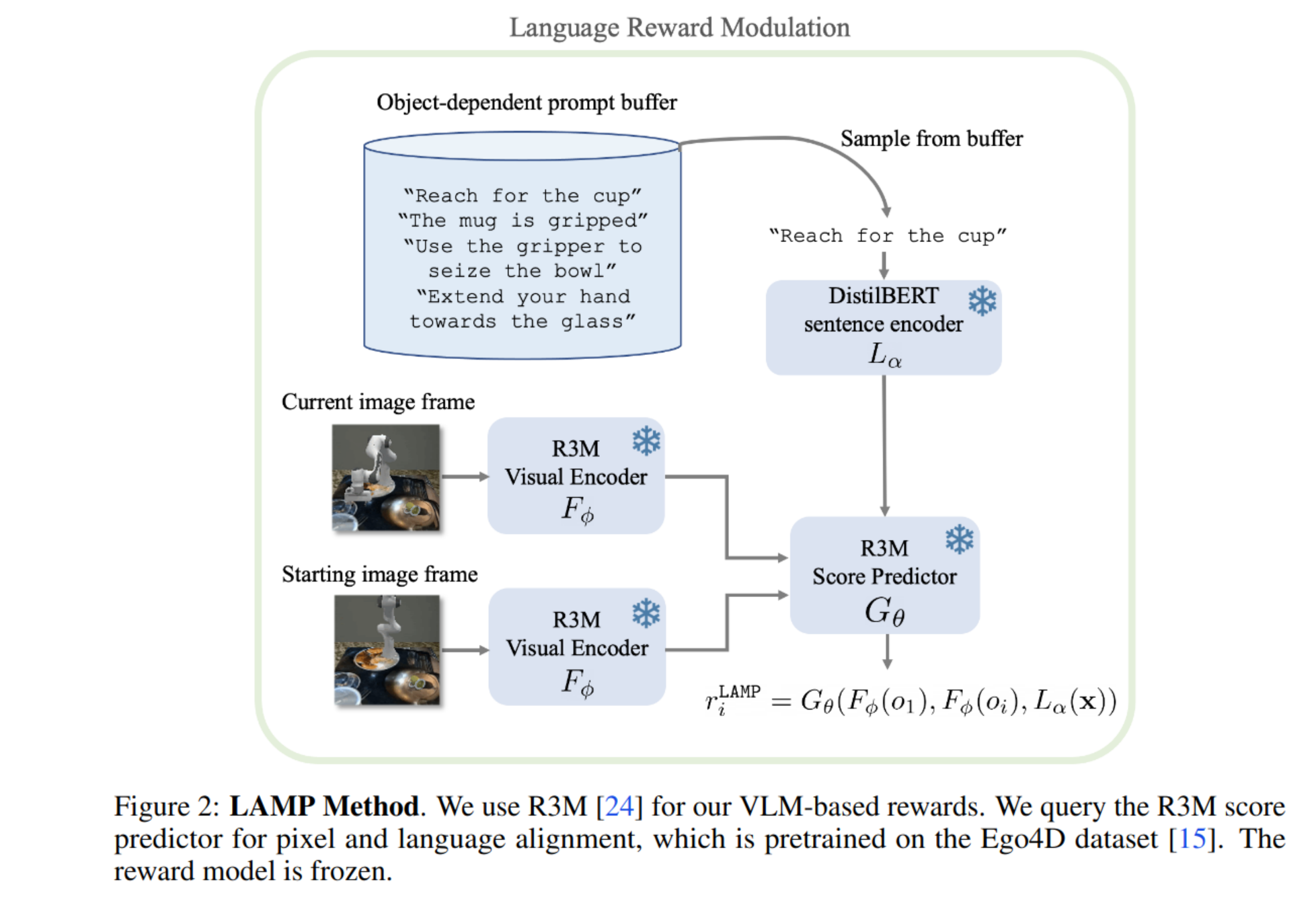
Summary of paper

Motivation
Learned reward function (LRF) are notorious for noise and reward misspecification errors
- which can render them highly unreliable for learning robust policies with RL
- due to issues of reward exploitation and noisy models that these LRF’s are ill-suited for directly learning downstream tasks.
Generalization ability issue of multi-modal vision and language model (VLM)
- nah, the author did not mention it
Contribution
- Using LAMP directly as a task reward would not enable the RL agents to solve any of the tasks. As we evidence in Figure 3, and motivate in the introduction, rewards from current pretrained VLMs are far too noisy and susceptible to reward exploitation to be usable with online RL. In fact, this is central to our message - current VLMs are ill-suited for this purpose in that they lack the required precision to supervise challenging robot manipulation tasks, however, they do possess certain properties that render them very useful for pretraining RL agents with limited supervision.
Results

Summary
Regrettably, the author did not provide compelling evidence to support the claim that the VLM reward signal is ineffective for training RL agents. Reviewers have requested further explanation on why VLM reward signals may fall short in training complex RL tasks.
Critics often counter with remarks such as, “If this is indeed a problem, why then do many studies successfully employ visual-text alignment based reward models?” So, it is very challenging to convince people that certain widely accepted methods may be flawed or inadequate. It’s a tough journey.
Additionally, the pretraining evaluation section in the paper does not substantiate the author’s assertion that the VLM reward signal is noisy and therefore unsuitable for training RL tasks. From the presented pretraining performance, it is not apparent whether the VLM pretraining results are suboptimal.
Potential future work
it is equivalent to use Language based signals and then abandon it.