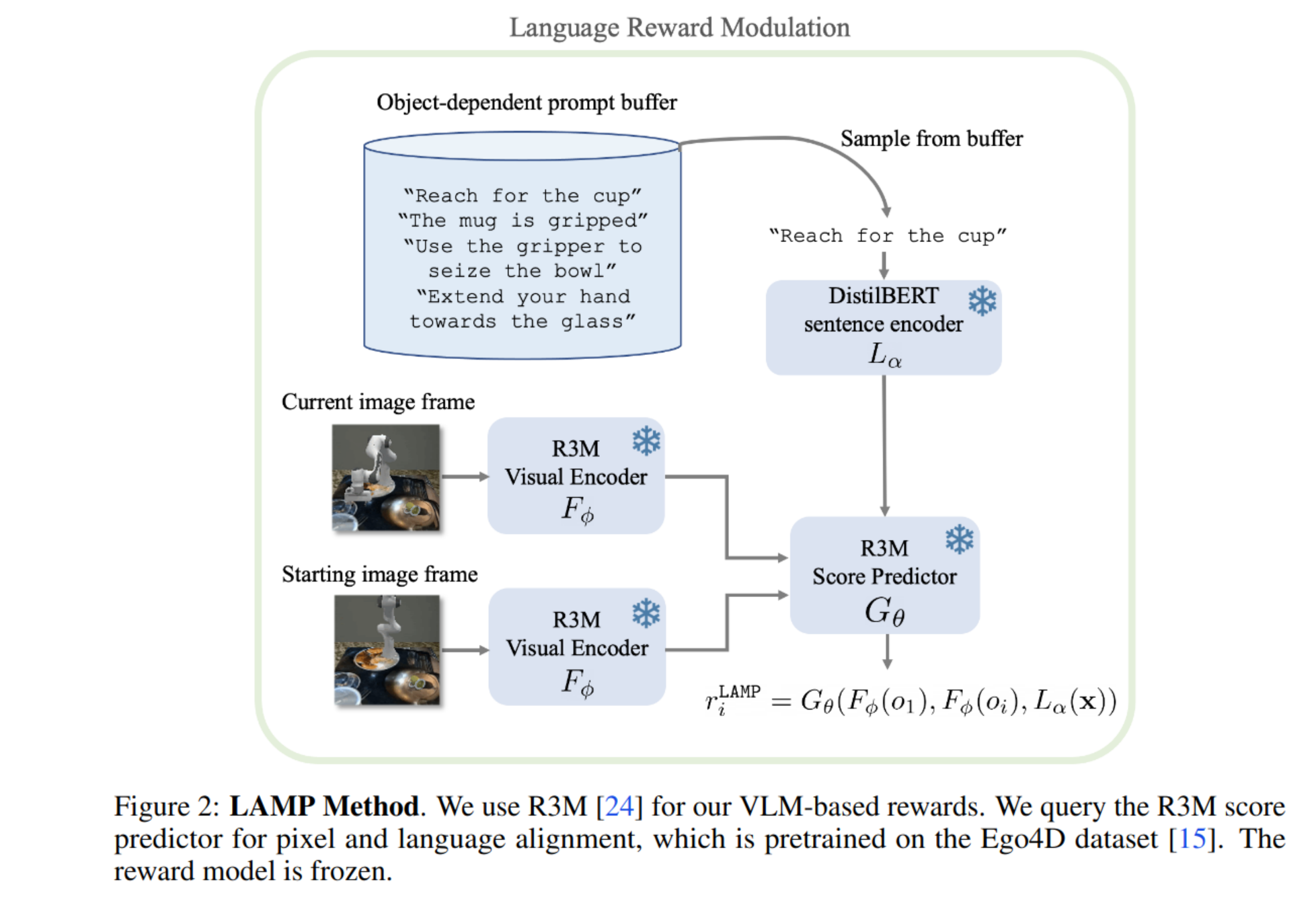
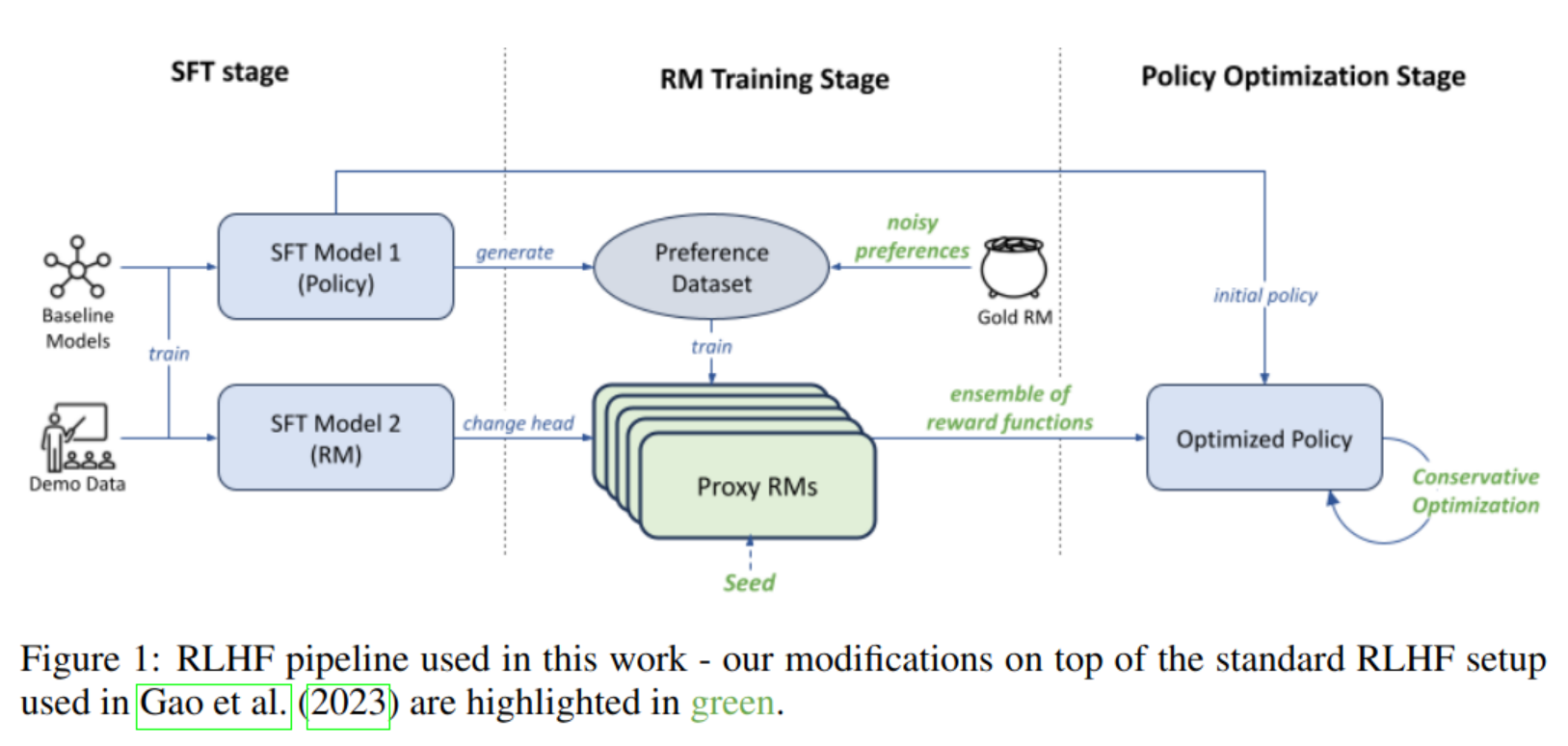
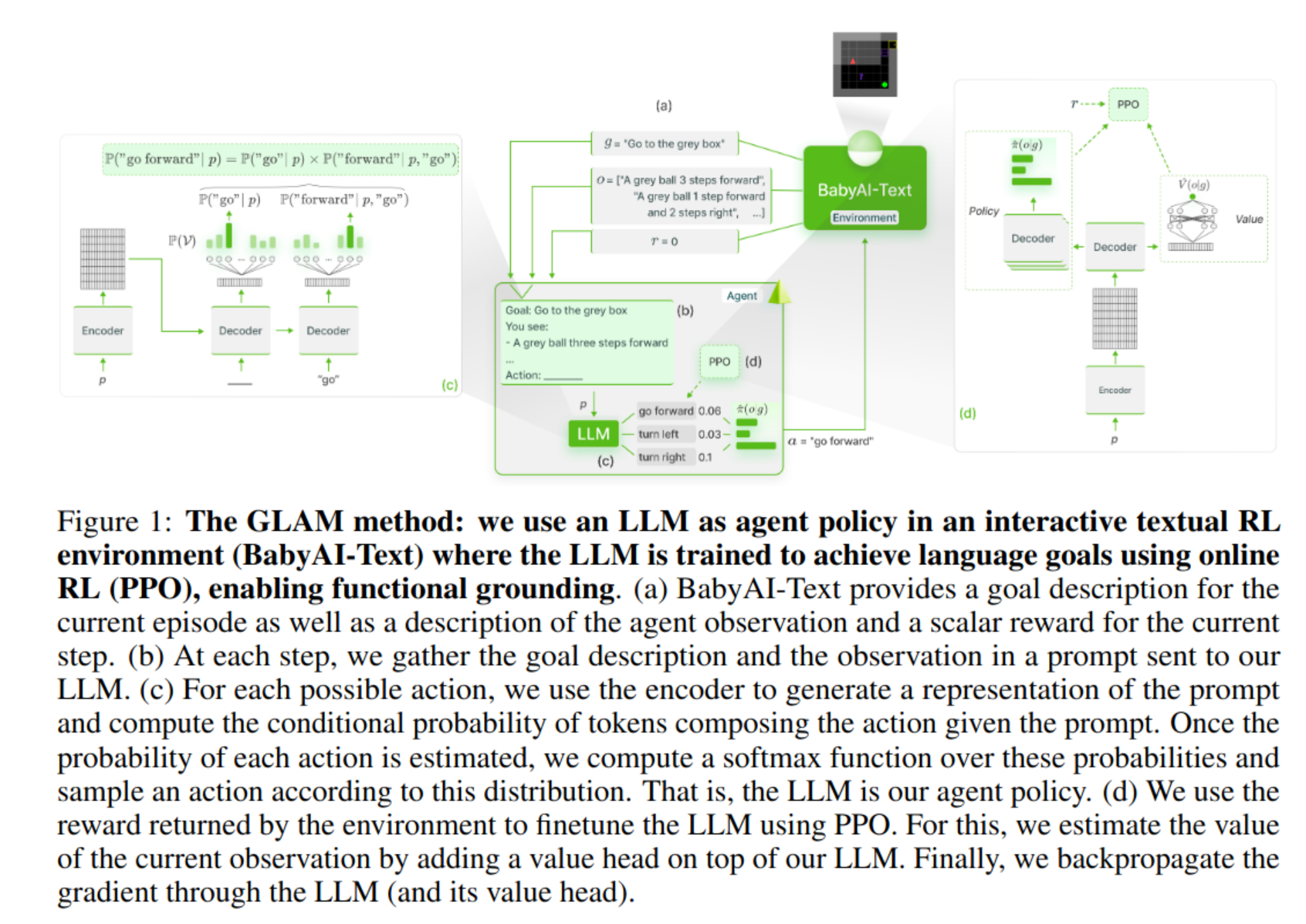
There are three papers from A.Prof. Hamid Rezatofighi :https://vl4ai.erc.monash.edu/positions.html
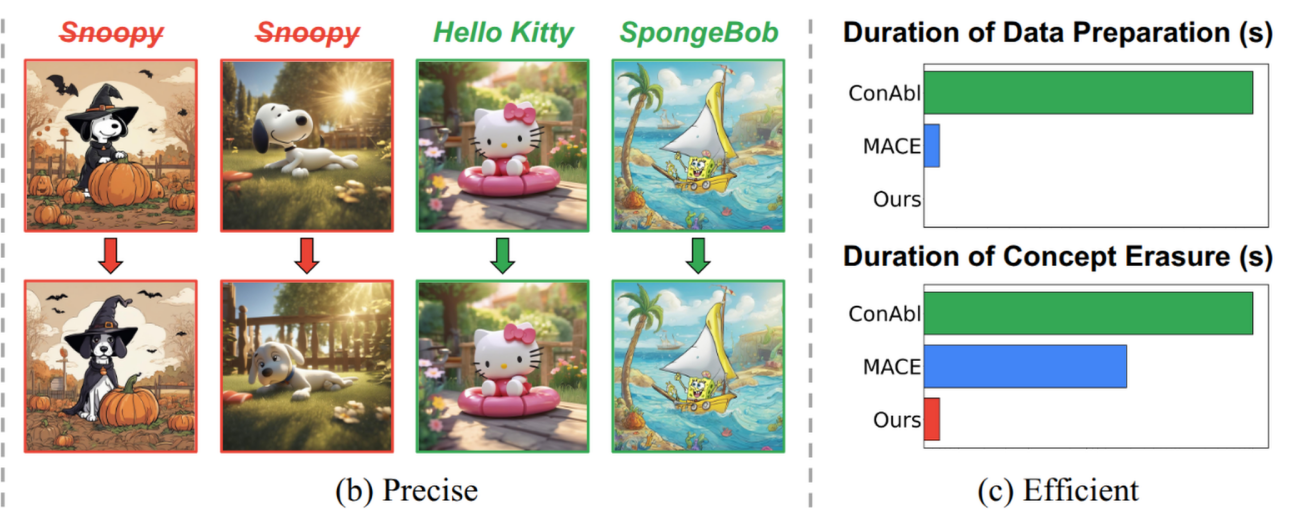
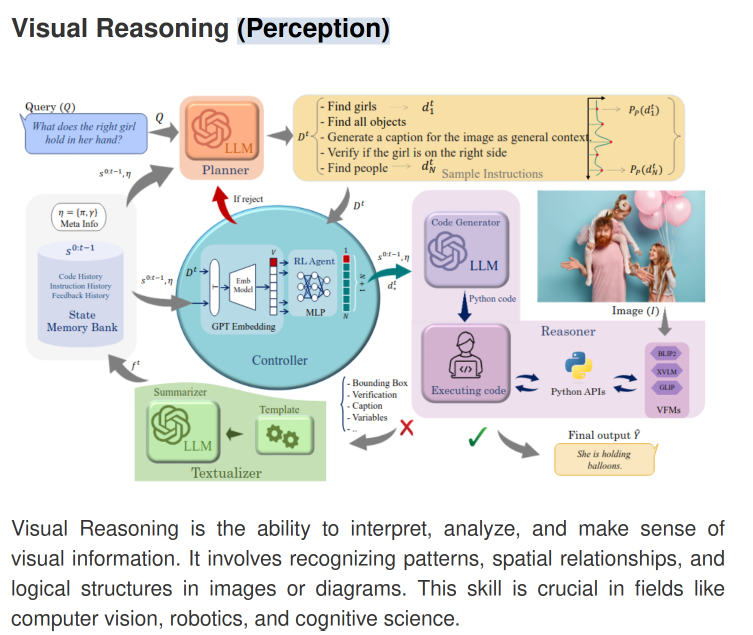
NAVER: A Neuro-Symbolic Compositional Automaton for Visual Grounding with Explicit Logic Reasoning NEUSIS: A Compositional Neuro-Symbolic Framework for Autonomous Perception, Reasoning, and Planning in Complex UAV Search Missions HYDRA: A Hyper Agent for Dynamic Compositional Visual Reasoning Multi-Objective Multi-Agent Planning for Discovering and Tracking Multiple Mobile Objects 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 # input bibtex here 1. @misc{cai2025naverneurosymboliccompositionalautomaton, title={NAVER: A Neuro-Symbolic Compositional Automaton for Visual Grounding with Explicit Logic Reasoning}, author={Zhixi Cai and Fucai Ke and Simindokht Jahangard and Maria Garcia de la Banda and Reza Haffari and Peter J. Stuckey and Hamid Rezatofighi}, year={2025}, eprint={2502.00372}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2502.00372}, } 2. @article{DBLP:journals/corr/abs-2409-10196, author = {Zhixi Cai and Cristian Rojas Cardenas and Kevin Leo and Chenyuan Zhang and Kal Backman and Hanbing Li and Boying Li and Mahsa Ghorbanali and Stavya Datta and Lizhen Qu and Julian Gutierrez Santiago and Alexey Ignatiev and Yuan{-}Fang Li and Mor Vered and Peter J. Stuckey and Maria Garcia de la Banda and Hamid Rezatofighi}, title = {{NEUSIS:} {A} Compositional Neuro-Symbolic Framework for Autonomous Perception, Reasoning, and Planning in Complex {UAV} Search Missions}, journal = {CoRR}, volume = {abs/2409.10196}, year = {2024} } 3. @inproceedings{DBLP:conf/eccv/KeCJWHR24, author = {Fucai Ke and Zhixi Cai and Simindokht Jahangard and Weiqing Wang and Pari Delir Haghighi and Hamid Rezatofighi}, title = {{HYDRA:} {A} Hyper Agent for Dynamic Compositional Visual Reasoning}, booktitle = {{ECCV} {(20)}}, series = {Lecture Notes in Computer Science}, volume = {15078}, pages = {132--149}, publisher = {Springer}, year = {2024} } 4. @article{DBLP:journals/tsp/NguyenVVRR24, author = {Hoa Van Nguyen and Ba{-}Ngu Vo and Ba{-}Tuong Vo and Hamid Rezatofighi and Damith C. Ranasinghe}, title = {Multi-Objective Multi-Agent Planning for Discovering and Tracking Multiple Mobile Objects}, journal = {{IEEE} Trans. Signal Process.}, volume = {72}, pages = {3669--3685}, year = {2024} } NAVER: A Neuro-Symbolic Compositional Automaton for Visual Grounding (https://arxiv.org/abs/2502.00372)
...