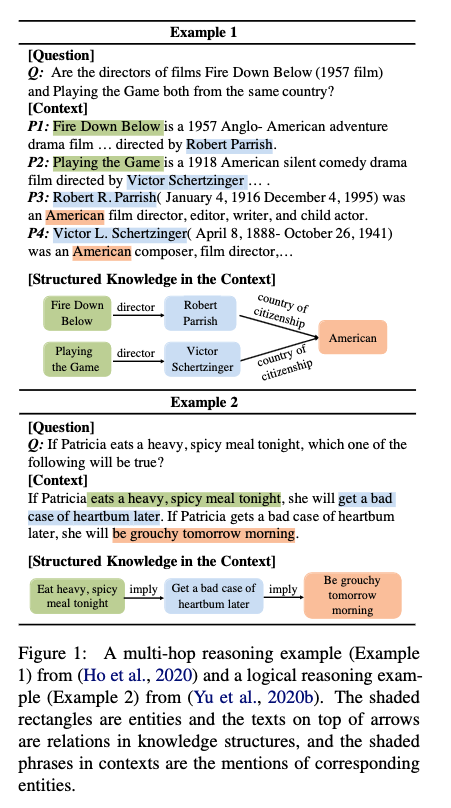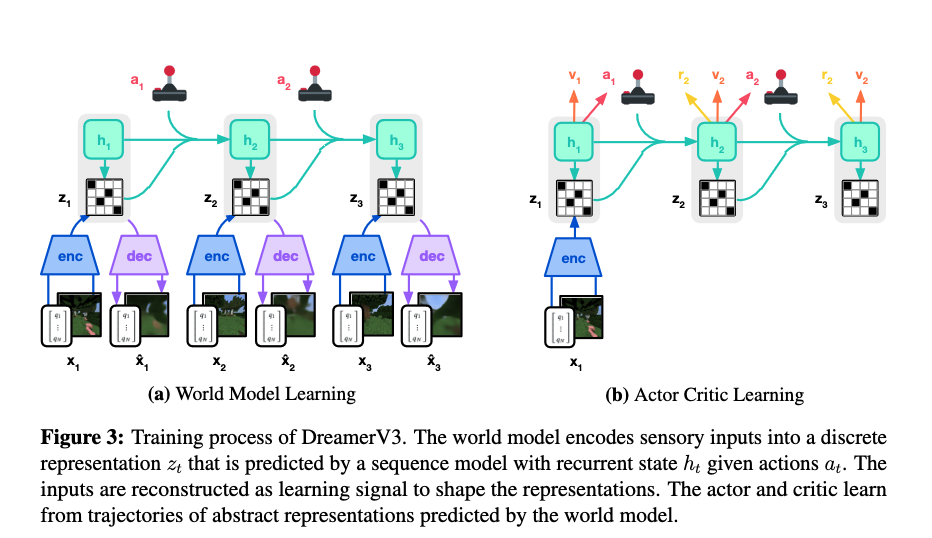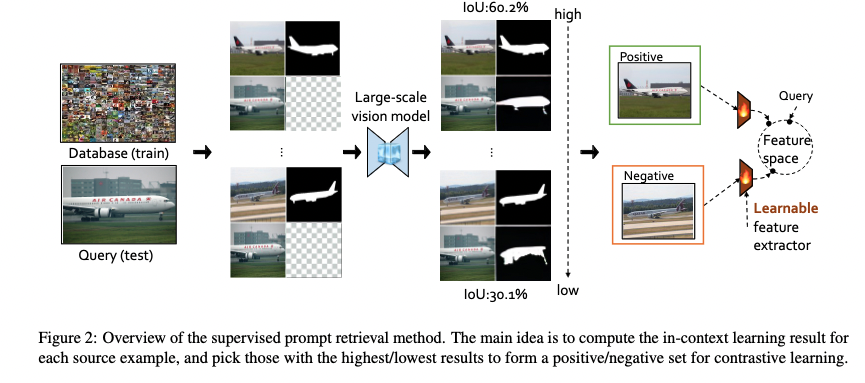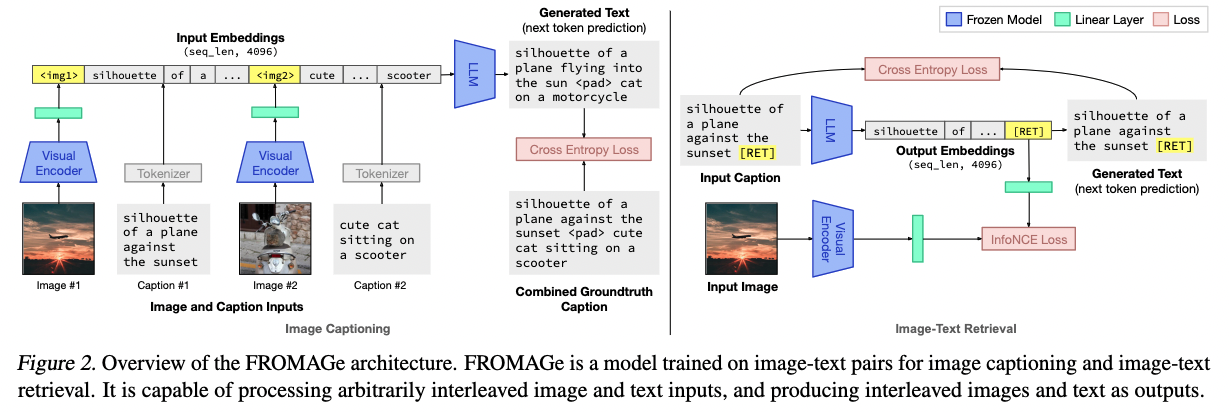
Zhuosheng_zhang Multimodal Chain of Thought Reasoning in Language Models 2023
[TOC] Title: Multimodal Chain of Thought Reasoning in Language Models Author: Zhuosheng Zhang et. al. Publish Year: 2023 Review Date: Wed, Feb 8, 2023 url: https://arxiv.org/pdf/2302.00923.pdf Summary of paper Motivation LLMs have shown impressive performance on complex reasoning by leveraging chain-of-thought (CoT) prompting to generate intermediate reasoning chains as the rationale to infer the answer. to elicit CoT reasoning in multimodality, a possible solution is to fine-tune small language models by fusing the vision and language features to perform CoT reasoning. The key challenge is that those language models tend to generate hallucinated reasoning chains that mislead the answer inference. Contribution We propose Mutimodal-CoT that incorporates vision features in a decoupled training framework. The framework separates the rationale generation and answer inference into two stages, the model is able to generate effective rationales that contribute to answer inference. Some key terms Multimodal-CoT ...