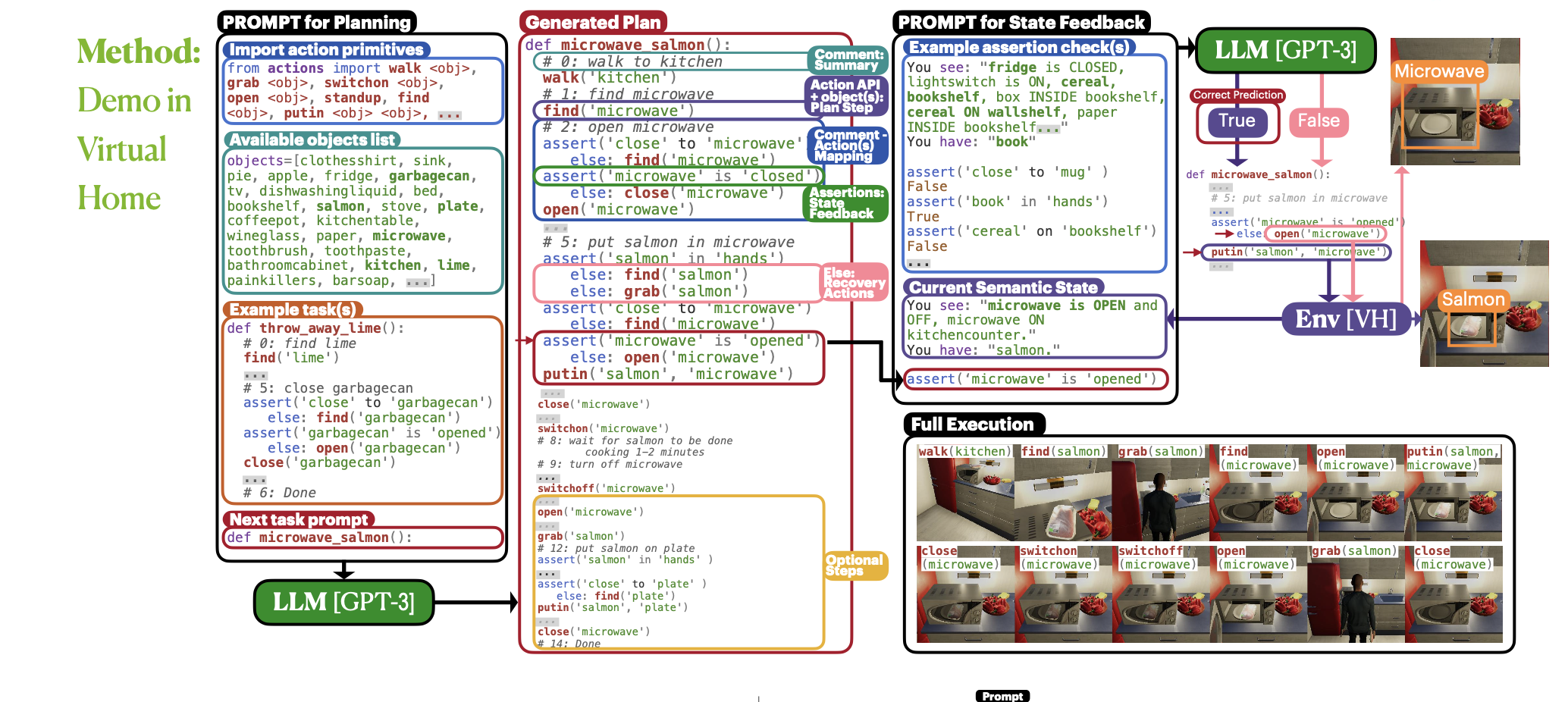
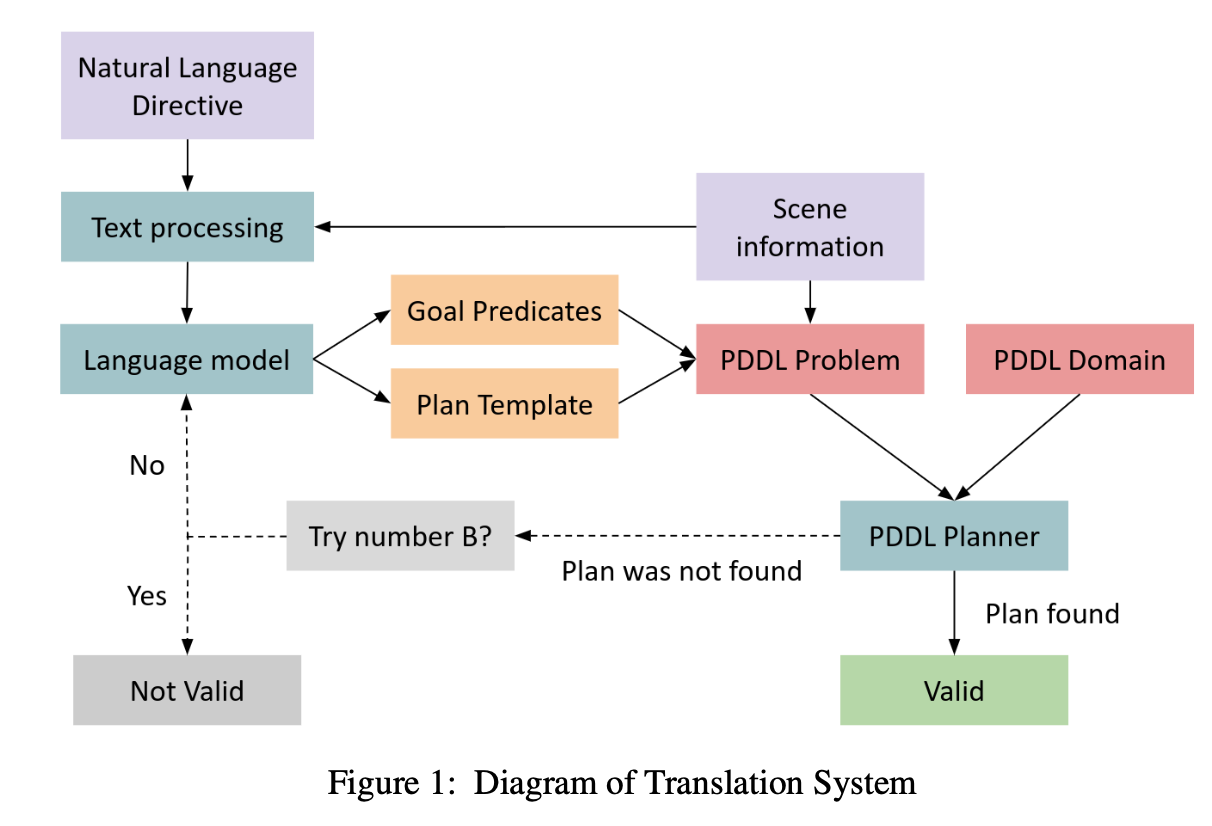
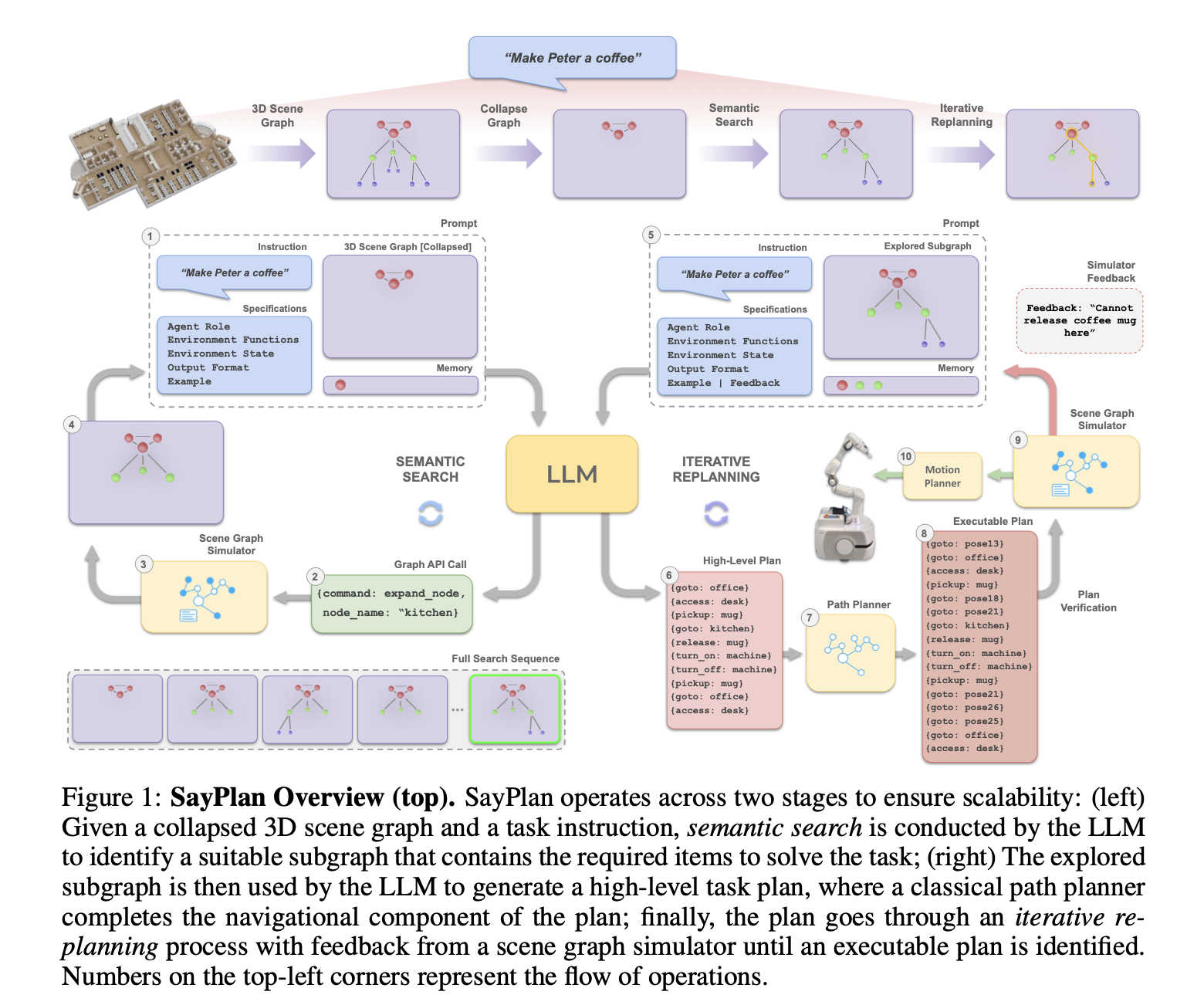
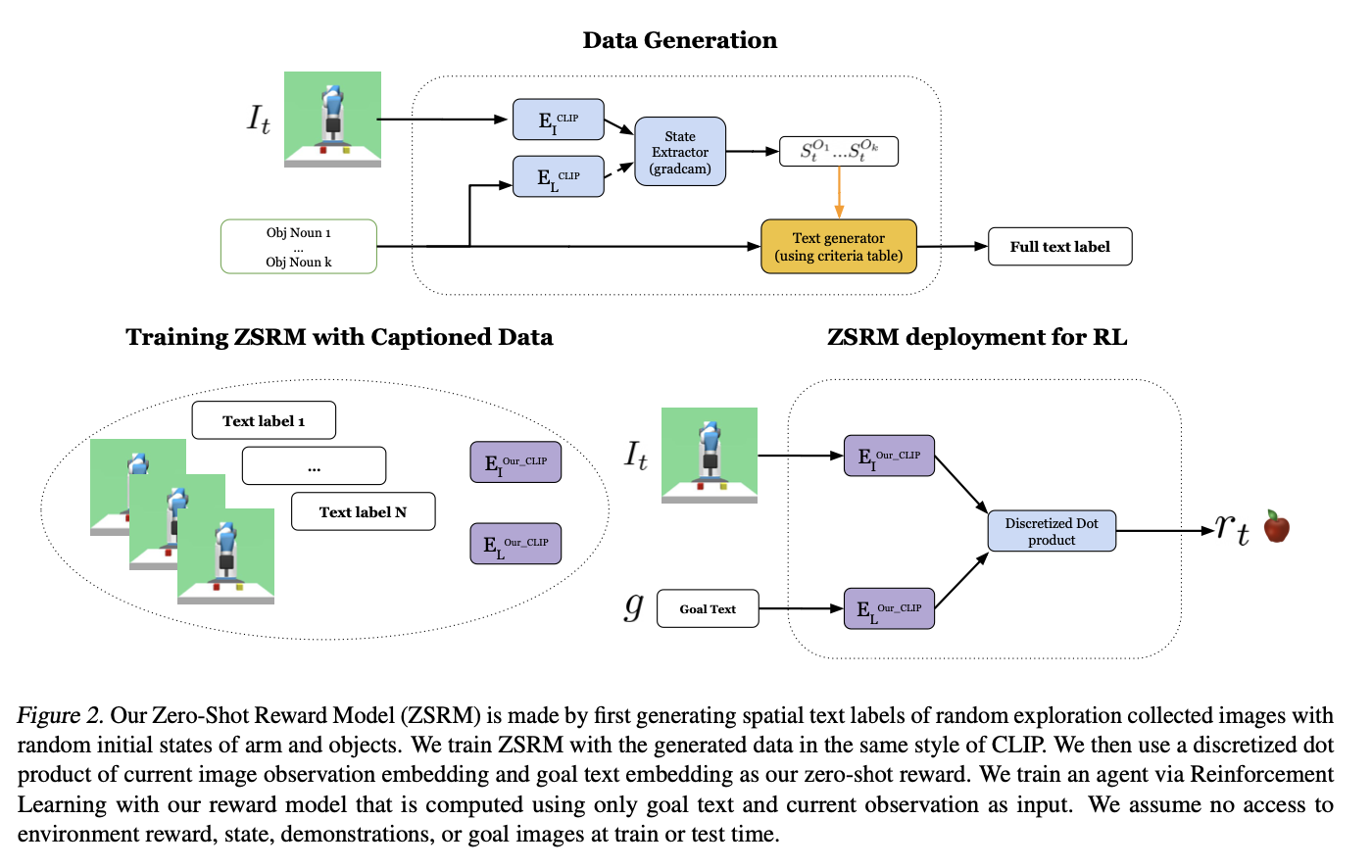
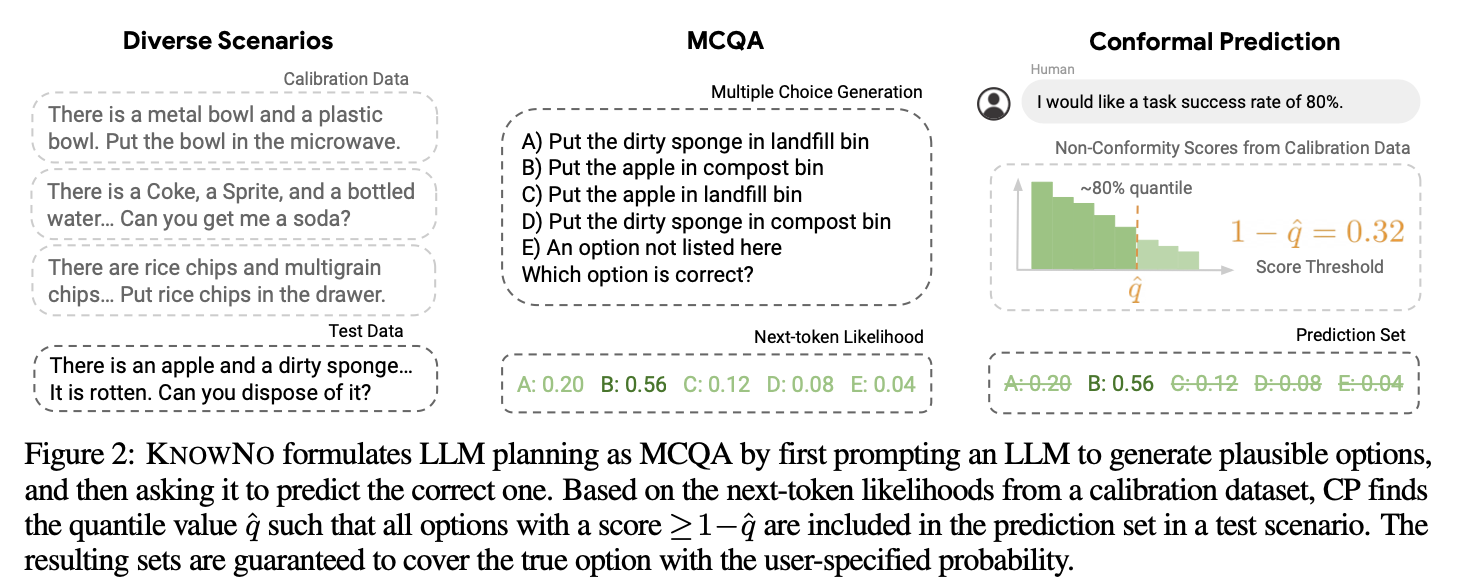
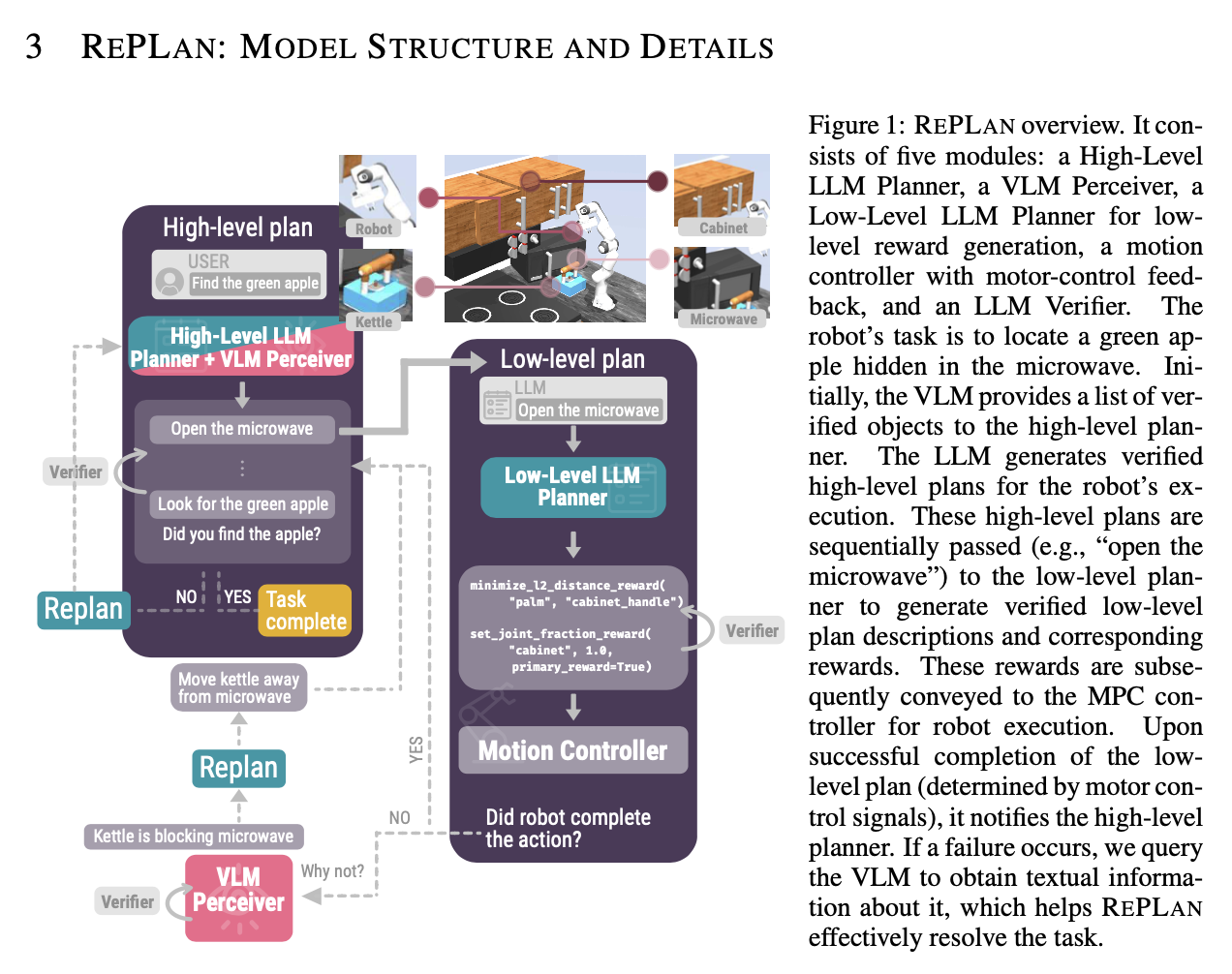
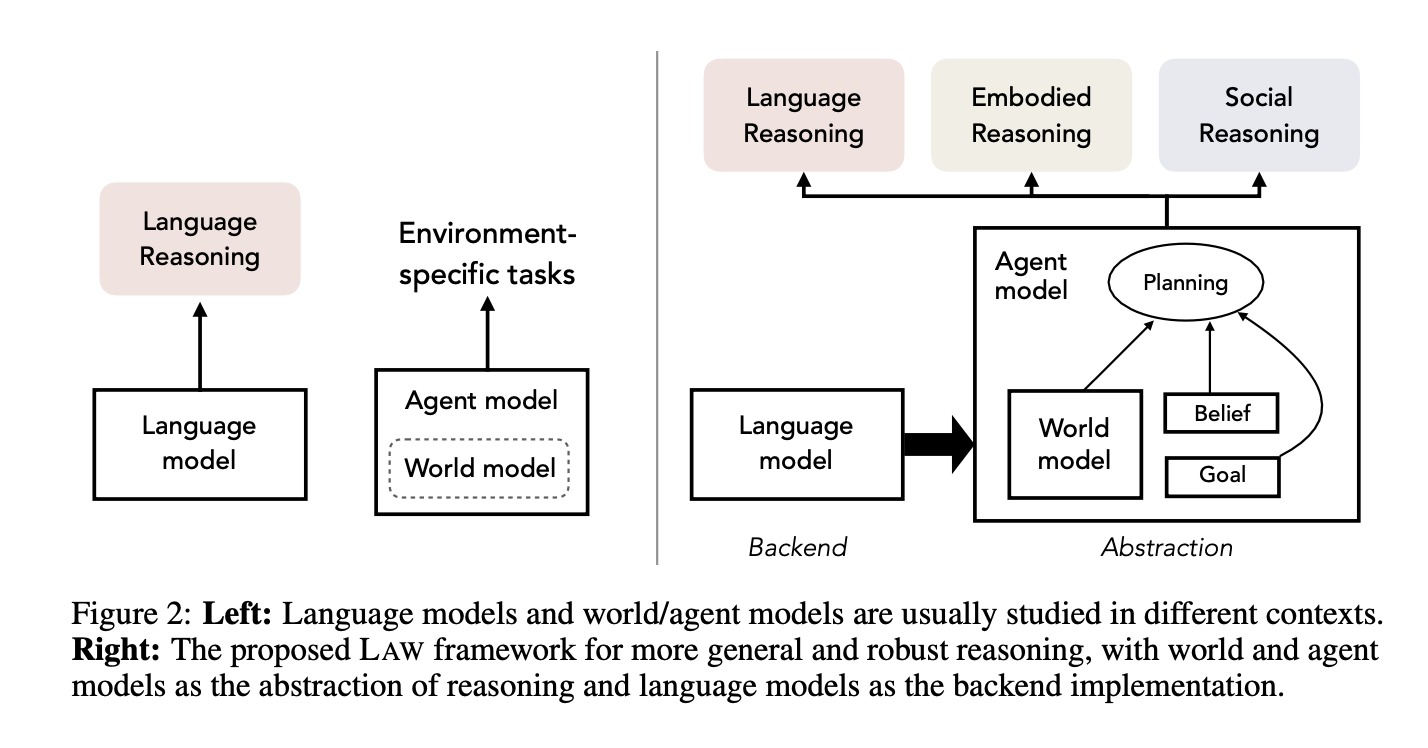
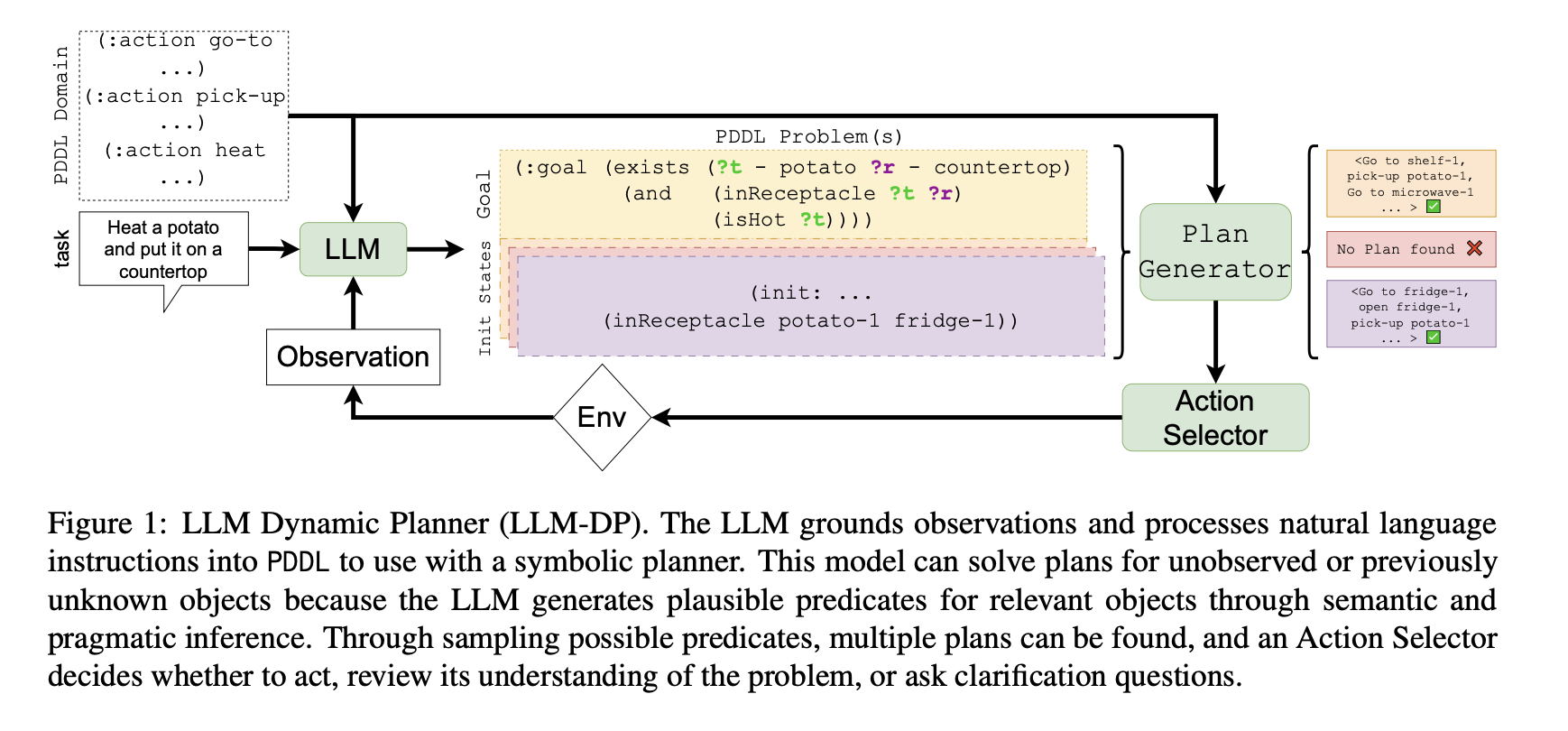
Vishal Pallagani Llm N Planning Survey 2024
[TOC] Title: “On the Prospects of Incorporating Large Language Models (LLMs) in Automated Planning and Scheduling (APS).” Author: Pallagani, Vishal, et al. Publish Year: arXiv preprint arXiv:2401.02500 (2024). Review Date: Mon, Jan 29, 2024 url: Summary of paper Contribution The paper provides a comprehensive review of 126 papers focusing on the integration of Large Language Models (LLMs) within Automated Planning and Scheduling, a growing area in Artificial Intelligence (AI). It identifies eight categories where LLMs are applied in addressing various aspects of planning problems: ...